

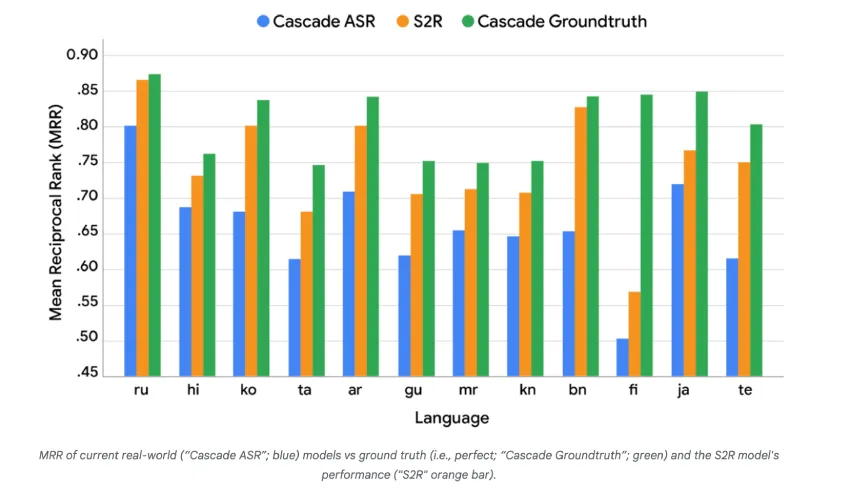


仓库向量搜索方法
Spring
·

Postgres与Qdrant:为何Postgres在AI和向量工作负载中胜出
DEV Community
·
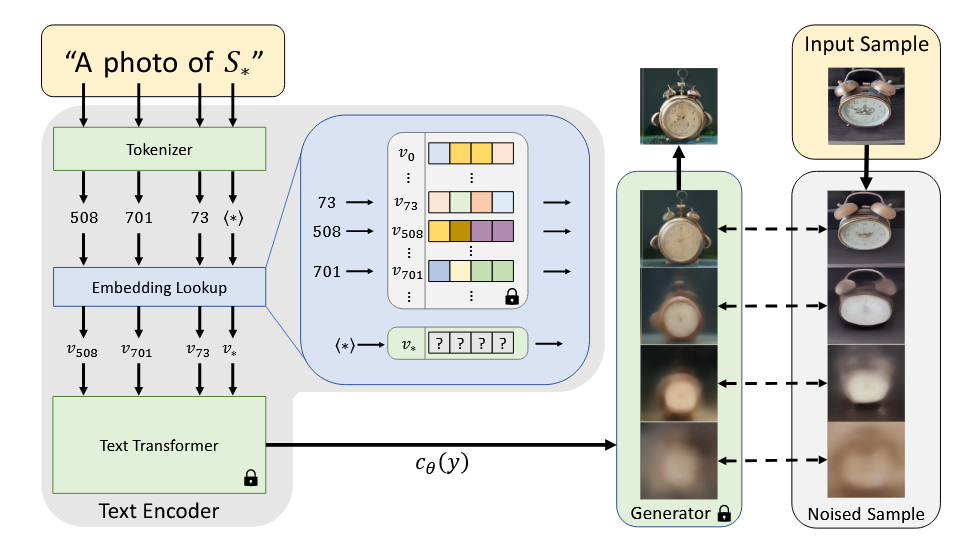

亚当·亨德尔:在Postgres上实现向量数据库的运营
Planet PostgreSQL
·

