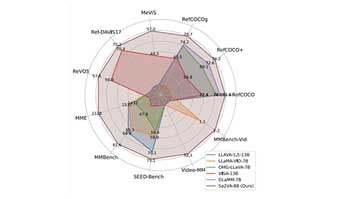
AIxiv报道了字节跳动与北大等机构联合提出的多模态大模型Sa2VA,该模型结合了SAM-2和LLaVA的优势,实现了视频和图像的细粒度理解,支持多种任务,表现优异。
多模态大型语言模型Sa2VA结合视频分割与语言处理,提升图像和视频理解效率。该模型采用创新的解耦设计和特殊标记机制,支持多任务,表现优于以往系统,标志着多模态AI的重大进步。
完成下面两步后,将自动完成登录并继续当前操作。