本文讨论了自监督视觉模型DINO及其在目标检测中的应用,重点介绍了Grounding DINO和DINO-X。Grounding DINO通过语言信息将闭集检测器扩展到开放集场景,采用双编码器-单解码器架构,结合图像和文本特征进行对象检测,创新设计了特征提取、增强和查询选择等方面,以提升检测性能。
本研究提出MGD-SAM2模型,旨在提高高分辨率无类别分割的细粒度细节分割精度。通过整合多视角特征,模型显著增强了局部细节和全局语义的提取能力,实验结果表明其在多个数据集上表现优异。
本研究提出了改进版SAM2模型,旨在提升图像和视频分割模型在跨领域适应性和泛化能力方面的表现。尽管特定领域适应性仍需进一步研究,但其在医疗成像等专业领域的应用潜力巨大。
AIxiv报道了字节跳动与北大等机构联合提出的多模态大模型Sa2VA,该模型结合了SAM-2和LLaVA的优势,实现了视频和图像的细粒度理解,支持多种任务,表现优异。
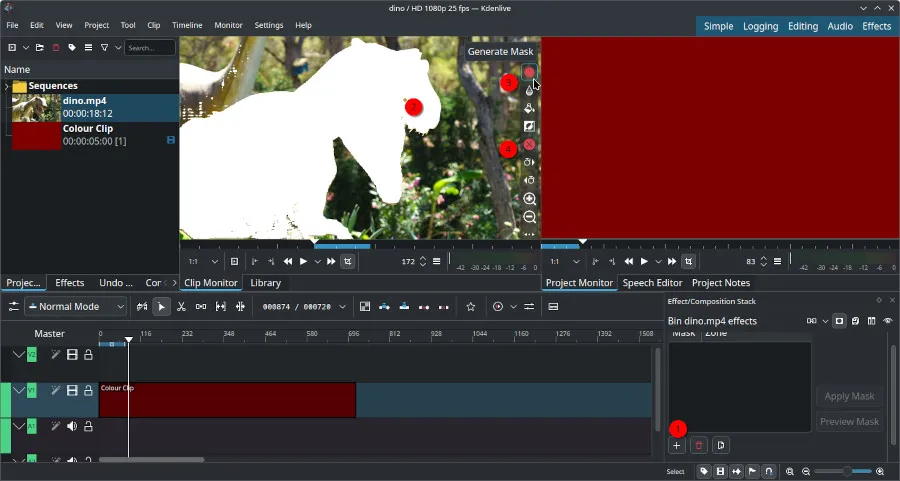
Kdenlive 是一款流行的开源视频编辑器,计划在 2025 年推出背景移除工具,目前已进入 alpha 测试阶段。该工具基于 SAM2 对象分割,支持 Linux 和 Windows 平台。
本研究提出了一种新的干扰物感知记忆模型SAM2.1++,旨在提高视觉物体跟踪的分割精度和稳定性。实验结果表明,该模型在七个基准测试中优于现有方法,并在六个测试中创下新纪录。
本研究探讨了Segment Anything Model 2(SAM2)在视频伪装目标分割(VCOS)中的应用和性能,解决了伪装物体难以检测的难题。研究中评估了SAM2在不同数据集上的表现,并通过与现有多模态大语言模型的整合及特定的数据集微调,发现SAM2在视频中的伪装物体检测中具备出色的零样本能力,这一能力可以通过调整参数进一步提升。
本研究针对现有医学图像分割模型在少量标注数据下表现不佳的问题,提出了一种新的方法FS-MedSAM2。通过充分利用SAM2的训练记忆注意模块和处理掩码提示的能力,该方法在两个公开医学图像数据集上超越了当前的最先进技术,展示了其显著的应用潜力。
本研究探讨了现有的分割基础模型在处理生物医学图像和视频方面的应用,尤其聚焦于SAM2模型的适用性和局限性。通过适应和微调,研究指出SAM2在不同数据集和任务中的表现存在差异,但在减少注释负担和实现零-shot分割方面展现出潜力。该工作强调了填补自然与医学图像领域差距的重要性,促进了临床应用的发展。
本研究解决了图像分割领域中强编码器缺乏的问题,提出了一个名为SAM2-UNet的框架,将Segment Anything Model 2作为编码器,与经典的U型解码器结合。实验结果表明,SAM2-UNet在多个下游任务中表现出优越性,超越了现有的专业最先进方法,具有广泛的应用潜力。
在最新一期的LWiAI播客中,主持人讨论了Instagram推出的AI功能,用户可以创建自己的AI版本。此外,Waymo在旧金山推出了无人驾驶汽车,NVIDIA面临芯片延迟问题。还提到Meta的AI Studio和Noam Shazeer重返谷歌,以及欧盟AI法案的实施和对谷歌的调查。
本文介绍了SAM-Adapter在医学图像分割中的应用,显著提升了分割性能,超越了现有技术。同时,研究探讨了SAM2在医学图像和视频中的表现,提出了AdapterShadow和Uncertainty-aware Adapter等新方法,展示了在阴影检测和医学图像分割中的优越性。
本研究将Segment Anything Model(SAM)应用于数字病理学的语义分割任务,通过可训练的类别提示和病理基础模型提升了分割能力。实验结果显示,微调方案在Dice和IOU得分上显著优于传统方法。尽管SAM在推理时间和泛化能力上表现良好,但在密集实例分割方面仍需改进,未来的微调可能有助于提升其性能。
Meta AI Research 的 Segment Anything Model 2 (SAM2) 是一个用于图像和视频分割的模型。研究发现,SAM2 在自动模式下的对象辨识能力有所下降,因此提出了针对水下领域的 USIS-SAM 模型,表现优异。此外,AquaSAM 在水下图像分割中超越了默认的 SAM 模型,尤其在复杂任务中提升了准确性。整体来看,SAM2 在医学图像分割等领域的应用前景广阔。
本文研究了Meta AI Research的分割模型SAM在伪装目标检测中的表现,并提出通过适配器提升其性能的可能性。尽管SAM在多个领域表现良好,但在透明物体检测中存在不足,尤其在安全关键场景中可能带来风险。研究呼吁对SAM进行进一步探索,以推动其在遥感图像分析等领域的应用。
Meta发布了第二代“Segment Anything AI”——SAM2,它现在可以进行实时视频分割和跟踪。该模型的代码、权重和数据集都是开源的。SAM2使用选择和细化的两步过程来交互式地分割视频中的对象。它还引入了一个记忆模块来处理视频分割中的对象运动、变形、遮挡和光照变化等挑战。该模型在一个名为SA-V的大规模数据集上进行了训练,该数据集包含51,000个真实世界的视频和600,000个时空掩模。SAM2能够处理长视频,并为模糊的对象生成多个掩模。该模型在解决过分分割问题方面表现出了良好的性能。然而,在某些情况下,它仍可能会丢失对象的跟踪,并且对于快速移动的对象可能会有困难。该模型是开源的,可免费使用。
完成下面两步后,将自动完成登录并继续当前操作。