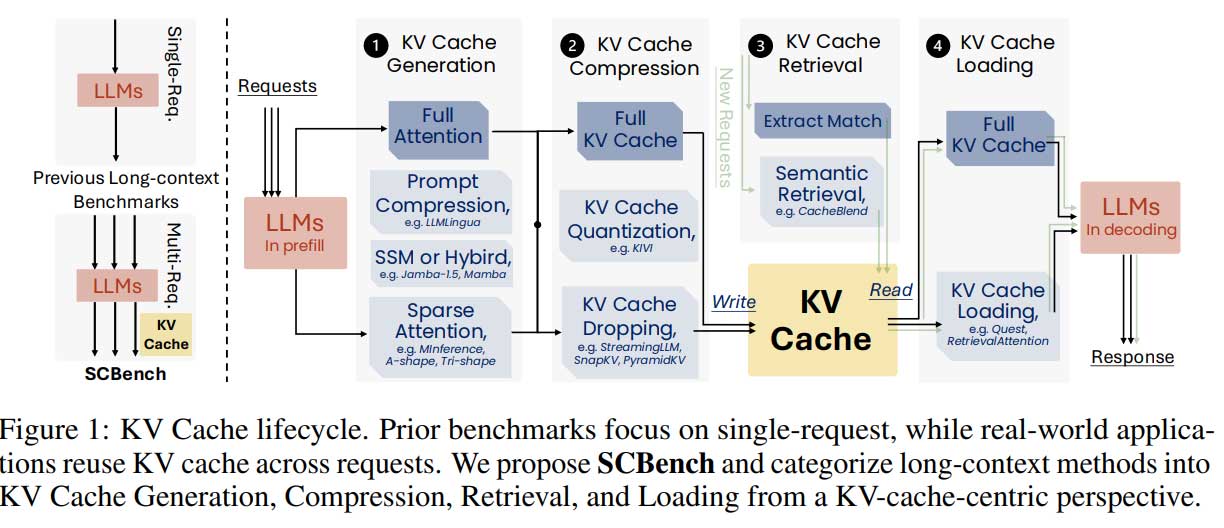
长上下文 LLM 在推理时面临计算和内存挑战。研究者推出 SCBench 基准测试,评估 KV 缓存的生成、压缩、检索和加载四个阶段,分析多轮交互中的性能。结果表明,O(n) 方法在多轮场景中表现优异,而 sub-O(n) 方法效果不佳,强调了评估长上下文方法的关键差距。
本研究解决了长上下文大型语言模型(LLMs)在计算和内存效率方面的挑战,提出了SCBench作为全面的基准测试框架,专注于KV缓存的生成、压缩、检索和加载。研究发现,动态稀疏性在KV缓存中表现出更强的表达能力,同时强调了在多轮场景中,子O(n)内存方法的不足及关注分布转移问题的影响。
完成下面两步后,将自动完成登录并继续当前操作。