
Microsoft AI 推出 SCBench:用于评估大型语言模型中长上下文方法的综合基准
内容提要
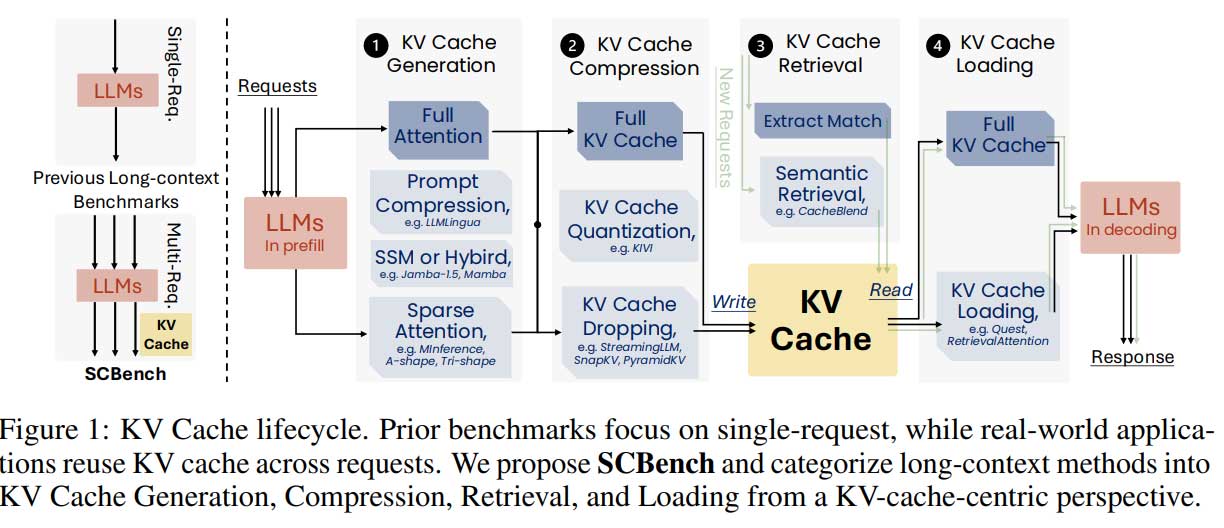
长上下文 LLM 在推理时面临计算和内存挑战。研究者推出 SCBench 基准测试,评估 KV 缓存的生成、压缩、检索和加载四个阶段,分析多轮交互中的性能。结果表明,O(n) 方法在多轮场景中表现优异,而 sub-O(n) 方法效果不佳,强调了评估长上下文方法的关键差距。
关键要点
-
长上下文 LLM 支持从 128K 到 10M 个 token 的扩展上下文窗口,适用于高级应用。
-
推理过程中面临计算效率和内存使用的挑战,KV 缓存优化旨在提高多轮交互中的缓存重用率。
-
现有技术如 PagedAttention 和 RadixAttention 通常仅在单轮场景中评估,忽略多轮应用。
-
SCBench 基准测试评估 KV 缓存的生成、压缩、检索和加载四个阶段,涉及 12 个任务和多轮、多请求的共享上下文模式。
-
研究结果显示,O(n) 内存方法在多轮场景中表现优异,而 sub-O(n) 方法效果不佳。
-
SCBench 深入分析了稀疏效应、任务复杂性和长生成场景中的分布变化等挑战。
-
基准测试评估了六种开源长上下文 LLM,实验在 NVIDIA A100 GPU 上进行,使用 BFloat16 精度。
-
测试了八种长上下文解决方案,结果表明 MInference 在检索任务中表现出色,A-shape 和 Tri-shape 在多轮任务中表现良好。
-
SSM-attention 混合体和门控线性模型在多轮交互中表现不佳,强调了评估长上下文方法的关键差距。
-
SCBench 从 KV 缓存生命周期的角度评估长上下文方法,为改进 LLM 和架构提供了宝贵的见解。
延伸解读
长上下文 LLM 的应用前景
长上下文 LLM 的扩展能力使其在复杂应用中具有广泛前景,如长文档问答和代码分析。然而,推理过程中的计算和内存挑战仍需解决,特别是在多轮交互场景中。SCBench 基准测试的推出,正是为了填补这一评估空白,帮助研究者更好地理解和优化这些模型的性能。
KV 缓存优化的重要性
KV 缓存的优化在长上下文 LLM 中至关重要,尤其是在多轮交互中。SCBench 通过分析 KV 缓存的生成、压缩、检索和加载四个阶段,揭示了不同方法在性能上的差异。研究表明,O(n) 方法在多轮场景中表现优异,而 sub-O(n) 方法则存在明显不足,提示开发者在选择技术时需谨慎。
评估方法的局限性
传统的评估方法往往侧重于单轮交互,忽视了多轮共享上下文的实际应用场景。SCBench 的引入为研究者提供了新的视角,强调了在多轮任务中评估长上下文 LLM 的必要性。这一变化可能会推动更符合实际需求的技术发展,提升模型在真实世界中的应用效果。
延伸问答
SCBench 基准测试的主要目的是什么?
SCBench 基准测试旨在评估大型语言模型中长上下文方法的性能,特别是 KV 缓存的生成、压缩、检索和加载四个阶段。
长上下文 LLM 在推理过程中面临哪些挑战?
长上下文 LLM 在推理过程中面临计算效率和内存使用的挑战,尤其是在多轮交互中。
O(n) 和 sub-O(n) 方法在多轮场景中的表现如何?
研究结果显示,O(n) 方法在多轮场景中表现优异,而 sub-O(n) 方法效果不佳。
SCBench 基准测试评估了哪些任务?
SCBench 基准测试评估了 12 个任务,包括字符串和语义检索、多任务处理和全局处理。
哪些技术被用于优化长上下文 LLM 的推理?
用于优化长上下文 LLM 推理的技术包括稀疏注意、线性注意和快速压缩等预填充优化。
SCBench 如何分析 KV 缓存的生命周期?
SCBench 从生成、压缩、检索和加载四个阶段分析 KV 缓存的生命周期,以评估长上下文方法。
