
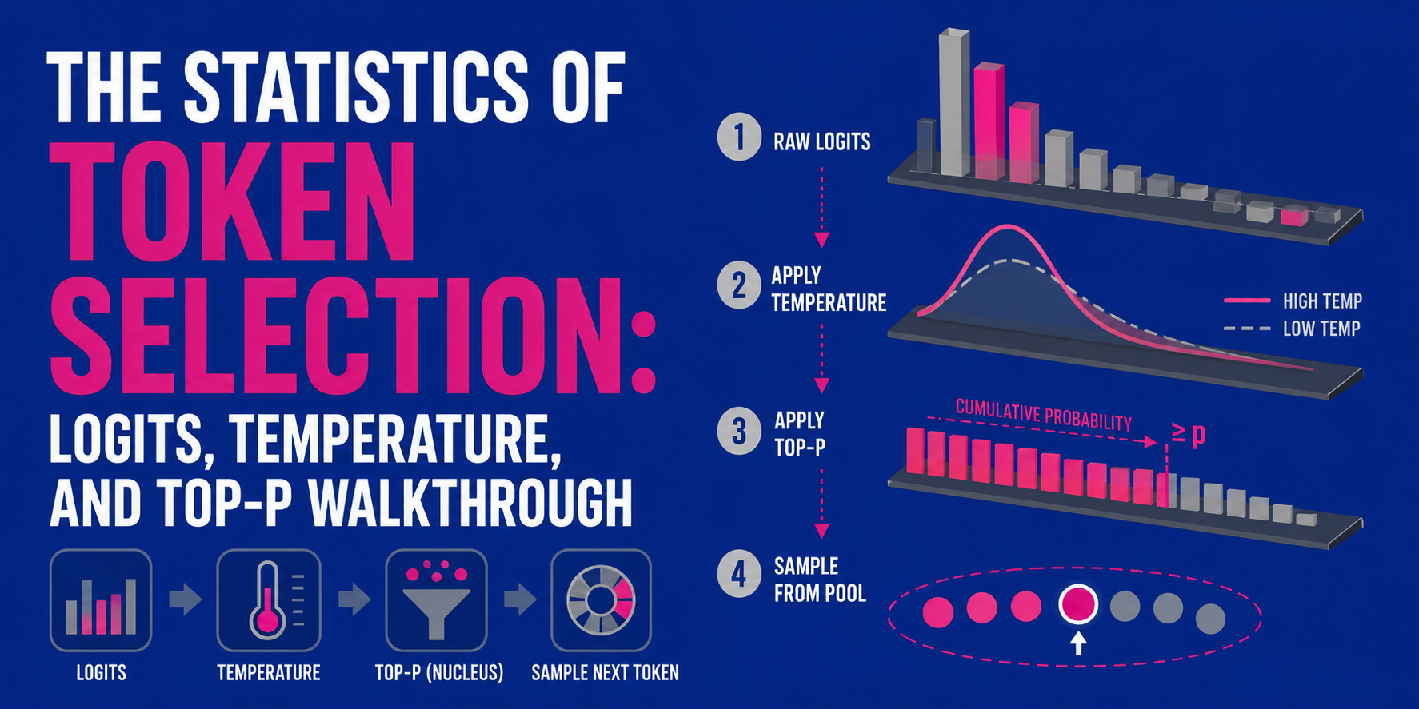
令牌选择的统计:Logits、温度与Top-P采样详解
MachineLearningMastery.com
·

大型语言模型如何选择词汇:Logits、Softmax与采样的实用指南
MachineLearningMastery.com
·

理解变换器中的文本生成参数
MachineLearningMastery.com
·
