
令牌选择的统计:Logits、温度与Top-P采样详解
内容提要
本文探讨了大语言模型(LLM)中令牌选择的统计过程,包括logits、温度和top-p采样。logits是模型输出的原始分数,温度用于调整概率分布的平滑程度,top-p则限制候选令牌的范围。通过这些参数的组合,模型在生成输出时能够平衡确定性与创造性。开发者需根据不同应用场景选择合适的温度和top-p值,以实现最佳效果。
关键要点
-
大语言模型(LLM)在生成输出时,涉及多个标准,包括响应的相关性、一致性和创造性。
-
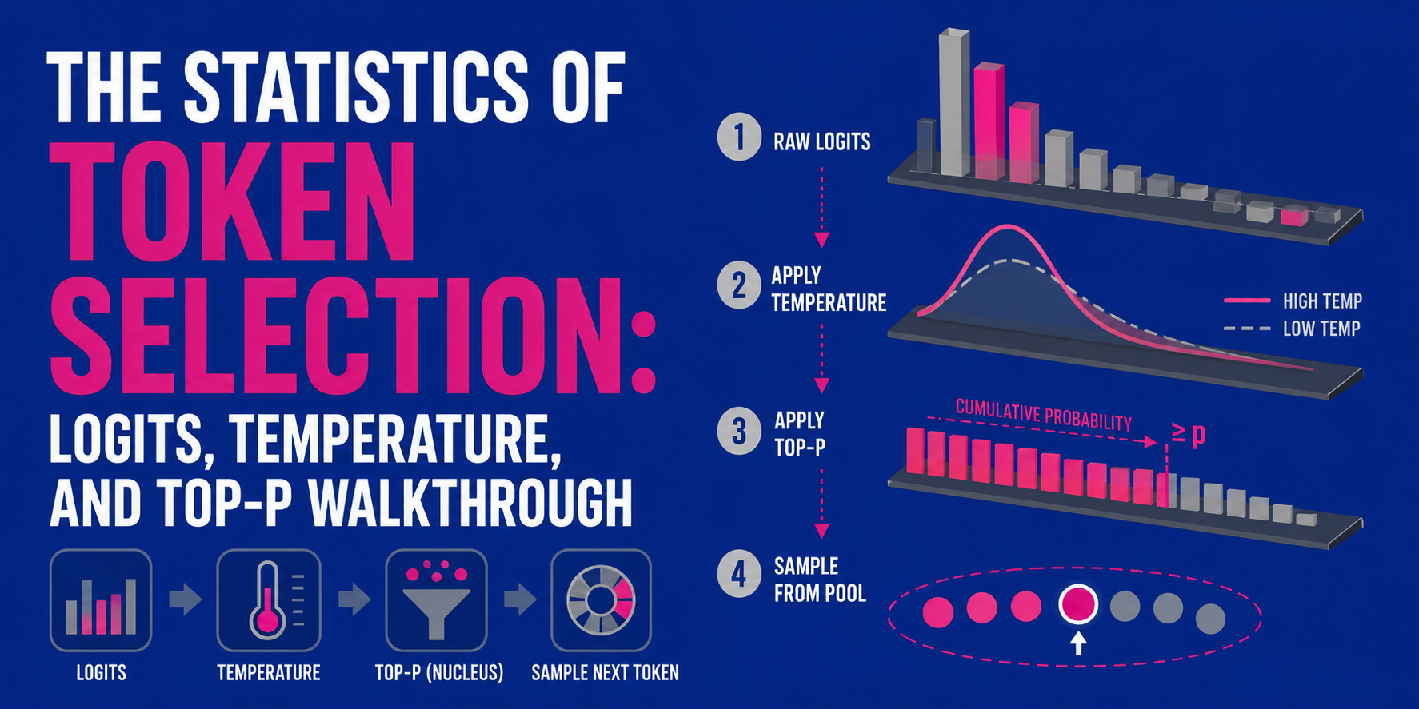
logits是神经网络中生成的原始分数,通常在最终线性层产生,用于表示可能的输出。
-
温度是应用于logits的缩放因子,高温度会使概率分布更均匀,增加不确定性和创造性;低温度则会增强高概率令牌的选择。
-
top-p(核采样)通过限制候选令牌的范围来控制随机性,选择累积概率达到阈值p的最小令牌集合。
-
logits、温度和top-p可以结合成一个多步骤的管道,用于生成LLM的输出,首先生成logits,然后应用温度和top-p进行筛选。
-
开发者需根据应用场景选择合适的温度和top-p值,以实现最佳效果,例如在高风险场景中使用低温度和严格的top-p,而在创造性领域中使用较高的温度和top-p。
延伸解读
理解Logits的作用
Logits是大语言模型生成输出的基础,代表了模型对每个可能令牌的原始评分。理解logits的生成过程有助于开发者优化模型的输出,确保生成的内容既相关又一致。通过调整logits,开发者可以影响模型在特定上下文中的表现,提升其在特定任务中的有效性。
温度与创造性的平衡
温度参数在模型生成过程中起着关键作用。高温度会增加输出的多样性和创造性,适合于需要创新的场景,如诗歌创作;而低温度则增强确定性,适合于高风险的应用,如法律分析。开发者应根据具体需求灵活调整温度,以实现最佳效果。
Top-P采样的灵活性
Top-p采样通过限制候选令牌的范围,提供了一种更灵活的随机性控制方式。与传统的top-k方法相比,top-p能够根据累积概率动态调整候选池,适应不同的生成需求。这种方法在需要平衡创造性与准确性的场景中尤为有效,开发者应重视其应用。
