Vearch是一个高效的分布式向量数据库,专为大规模向量相似度查询设计,集成数据管理、向量索引和检索,支持混合查询,易于使用,适合AI应用开发。项目使用C++实现,性能优越,社区活跃,适合学习和实际应用。
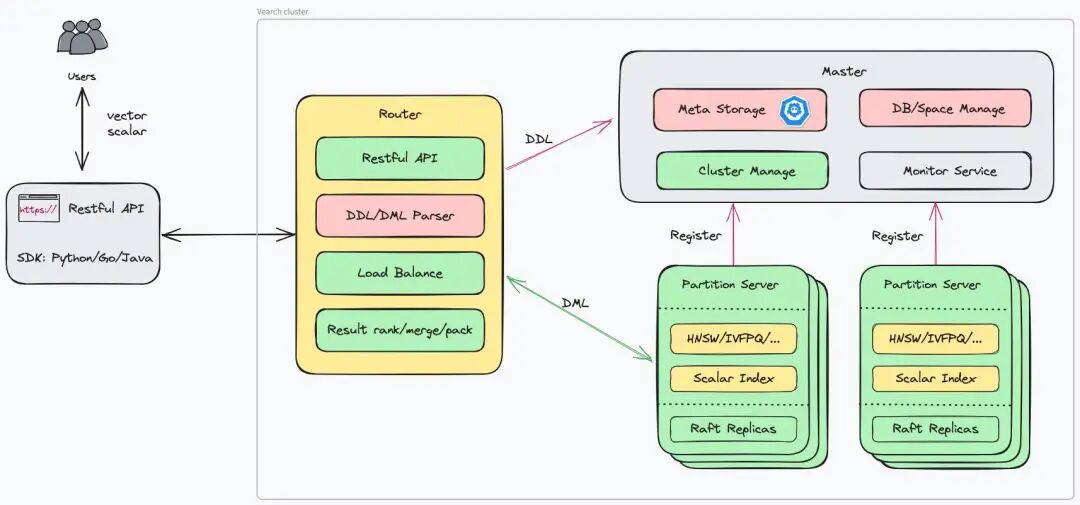
Vearch是一款开源的向量数据库,用于海量数据的近似检索。它基于Faiss的SIMD指令实现,支持分布式最邻近搜索算法。Vearch的功能满足要求,性能不错,但对新手来说可能有些麻烦。已被一些业务团队用于推荐和查重等业务能力。
本文介绍了京东内部向量数据库vearch的实践经验,包括文本转向量、向量维度、建表参数选择等。还介绍了分片数和副本数的评估方法,以及数据库中的数据记录和表结构。最后,指出向量数据库对大模型应用的重要性,并提出了一些优化方案。
该文介绍了京东健康如何使用开源的中文嵌入模型M3E来生成向量,并使用Vearch进行高性能相似搜索。Vearch是一个弹性分布式系统,支持CPU和GPU版本,实时添加数据到索引,支持多个向量字段和批量操作,支持数值字段范围过滤和字符串字段标签过滤,支持多种索引方式和Python SDK本地快速开发验证。同时,该文提供了向量生成示例和查询语句。
完成下面两步后,将自动完成登录并继续当前操作。