
分布式向量搜索的技术革命!看这个中国团队打造的AI引擎将如何重塑数据检索
内容提要
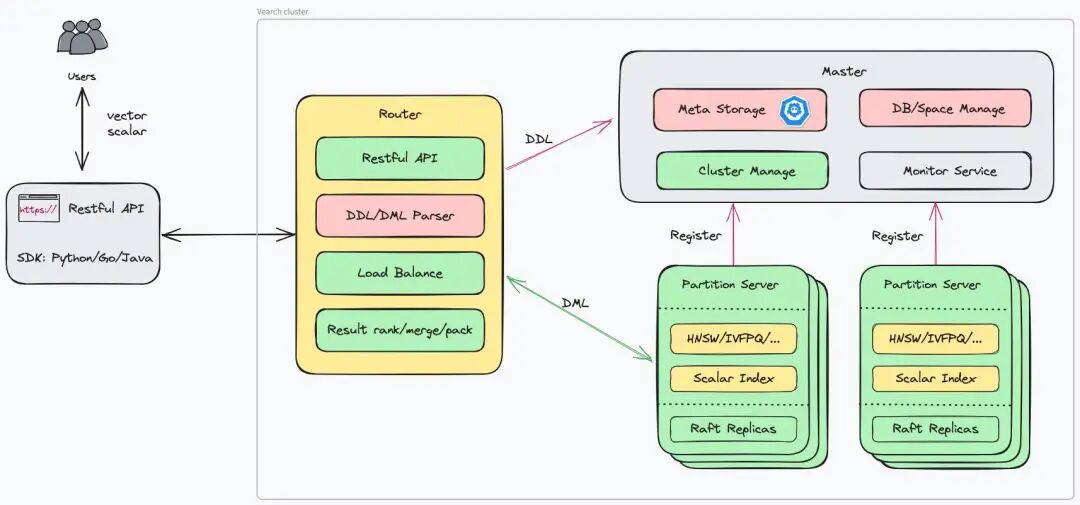
Vearch是一个高效的分布式向量数据库,专为大规模向量相似度查询设计,集成数据管理、向量索引和检索,支持混合查询,易于使用,适合AI应用开发。项目使用C++实现,性能优越,社区活跃,适合学习和实际应用。
关键要点
-
Vearch是一个高效的分布式向量数据库,专为大规模向量相似度查询设计。
-
集成数据管理、向量索引和检索,支持混合查询,适合AI应用开发。
-
应用特性包括一站式解决方案、混合检索、高吞吐低延迟、分布式架构和易用性强。
-
核心架构使用C++开发,数据存储采用RocksDB,支持多种向量索引算法。
-
部署过程简单,使用Docker和Docker Compose可以快速搭建。
-
推荐原因包括学习价值高、性能卓越、开箱即用和社区活跃。
延伸解读
分布式向量数据库的优势
Vearch作为分布式向量数据库,能够高效处理大规模向量相似度查询,特别适合AI应用开发。其一站式解决方案集成了数据管理、向量索引和检索,简化了开发流程,降低了技术门槛。对于需要处理海量非结构化数据的开发者来说,Vearch提供了一个理想的选择。
技术架构与性能
Vearch的核心架构使用C++开发,结合RocksDB进行数据存储,确保了高性能和高吞吐量。支持多种向量索引算法,使得在不同业务场景下能够灵活选择最优方案。这种技术架构使得Vearch在性能上能够与商业化产品竞争,适合对性能有高要求的应用场景。
易用性与部署
Vearch的部署过程相对简单,使用Docker和Docker Compose可以快速搭建。提供类似SQL的查询语言和丰富的API,降低了学习成本,适合各类开发者。对于希望快速实现向量搜索功能的团队,Vearch的易用性将大大提升开发效率。
延伸问答
Vearch是什么类型的数据库?
Vearch是一个高效的分布式向量数据库,专为大规模向量相似度查询设计。
Vearch的主要应用特性有哪些?
Vearch的主要应用特性包括一站式解决方案、混合检索、高吞吐低延迟、分布式架构和易用性强。
如何快速部署Vearch?
快速部署Vearch只需安装Docker和Docker Compose,拉取项目代码并使用docker compose命令启动服务,整个过程大约10分钟。
Vearch支持哪些开发语言?
Vearch支持多种开发语言,包括Python、Java和Go。
Vearch的核心架构使用了什么技术?
Vearch的核心架构使用C++开发,数据存储采用RocksDB。
为什么推荐使用Vearch?
推荐使用Vearch的原因包括学习价值高、性能卓越、开箱即用和社区活跃。
