

向量嵌入解析:从理论到实际应用
Redis Blog
·
动态分块用于 RAG:构建适应性上下文基础设施
Redis Blog
·

在Databricks上通过全文本搜索索引加速查询
Databricks
·

五个在生产中有效的上下文工程原则
Redis Blog
·

通过RedisVL MCP将您的Redis索引连接到AI代理
Redis Blog
·
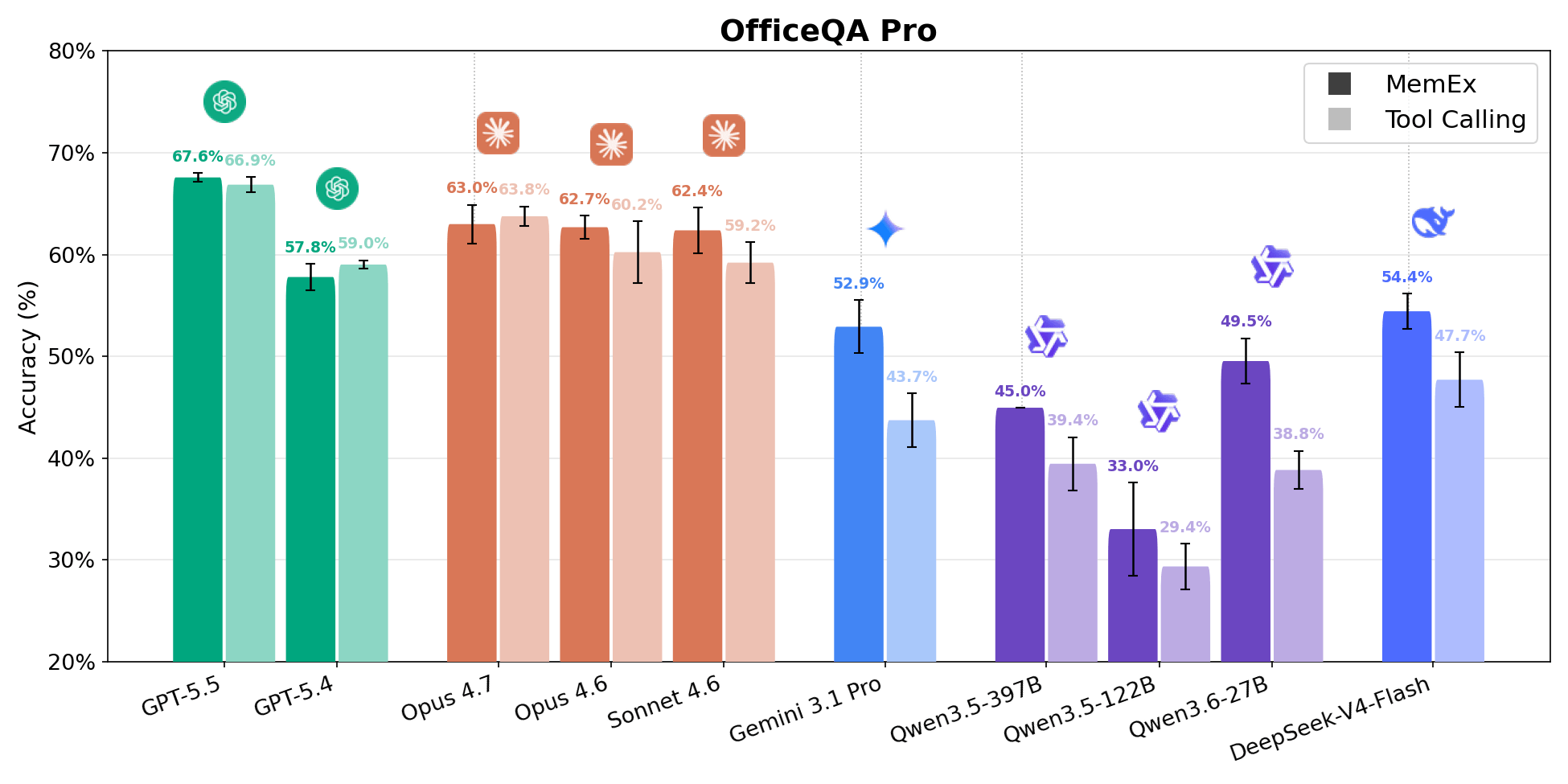
Elasticsearch 9.4 驱动 Elastic AI 生态系统的下一个阶段:与 NVIDIA 合作的 Dell AI 数据平台
Elastic Blog - Elasticsearch, Kibana, and ELK Stack
·

天鹜科技发布MatwingsVenus™,给AI一个共享实验室
HyperAI超神经
·

Kensho如何利用LangGraph构建多代理框架以解决可信金融数据检索
LangChain Blog
·

什么是键值数据库?
Redis Blog
·


什么是AI PaaS?人工智能开发的未来指南
The New Stack
·
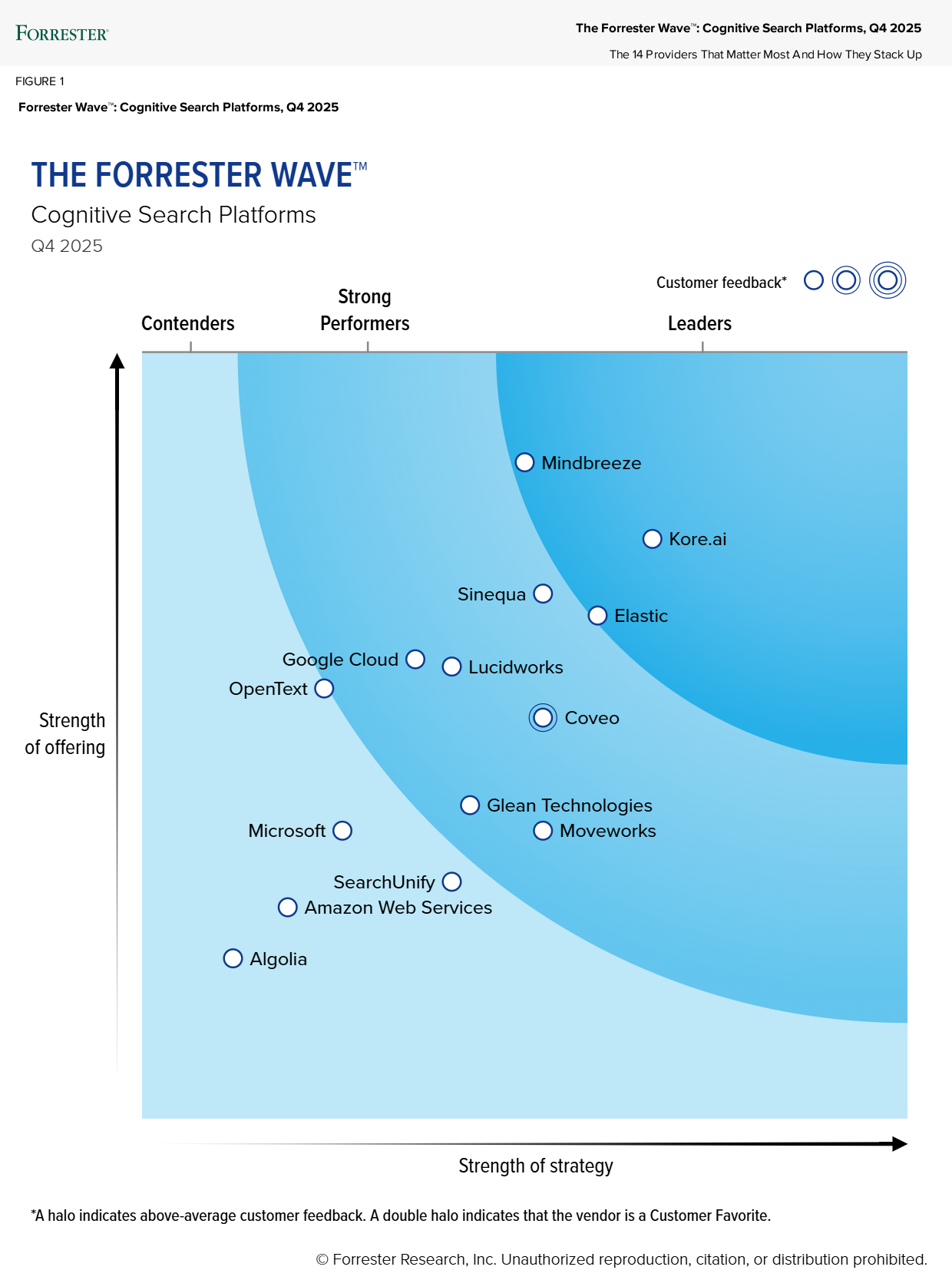
Elastic在2025年第四季度被评为Forrester Wave™认知搜索平台的领导者
Elastic Blog - Elasticsearch, Kibana, and ELK Stack
·
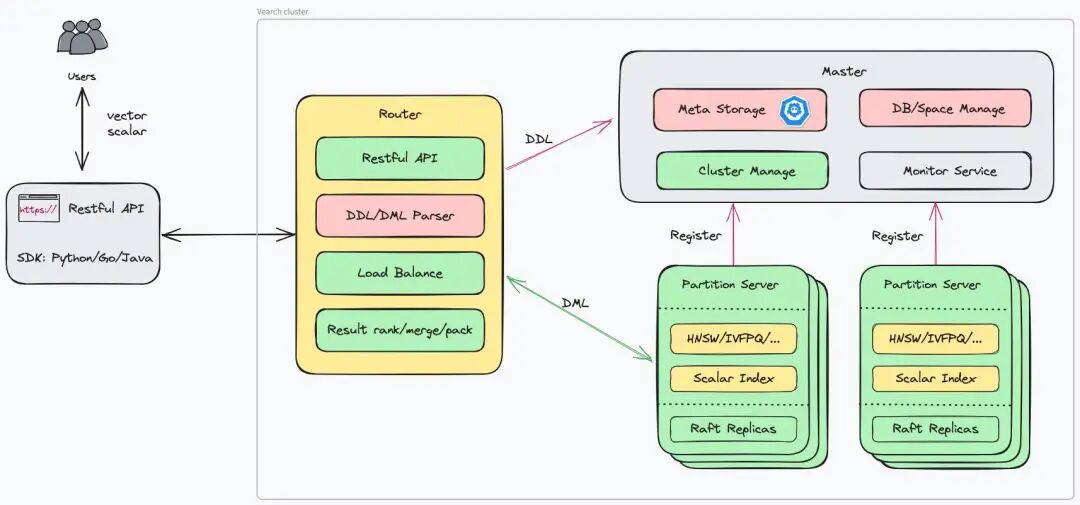
分布式向量搜索的技术革命!看这个中国团队打造的AI引擎将如何重塑数据检索
dotNET跨平台
·
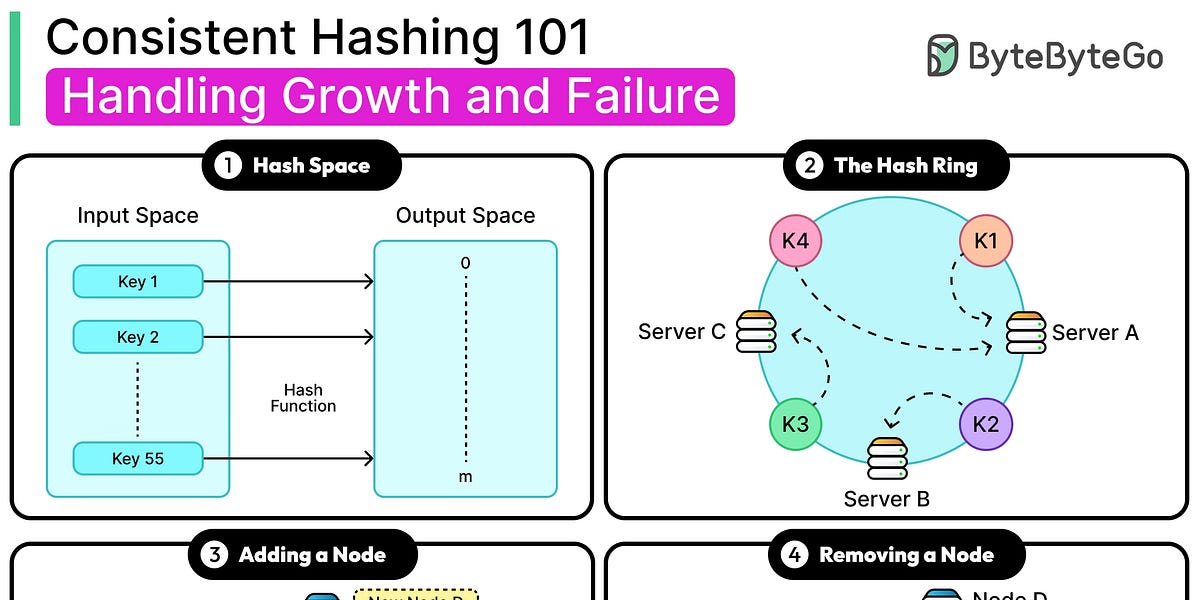
一致性哈希基础:现代系统如何应对增长与故障
ByteByteGo Newsletter
·
-bux7g5ul1h.png)
通过MongoDB和IBM Watsonx.ai转型金融服务
MongoDB
·
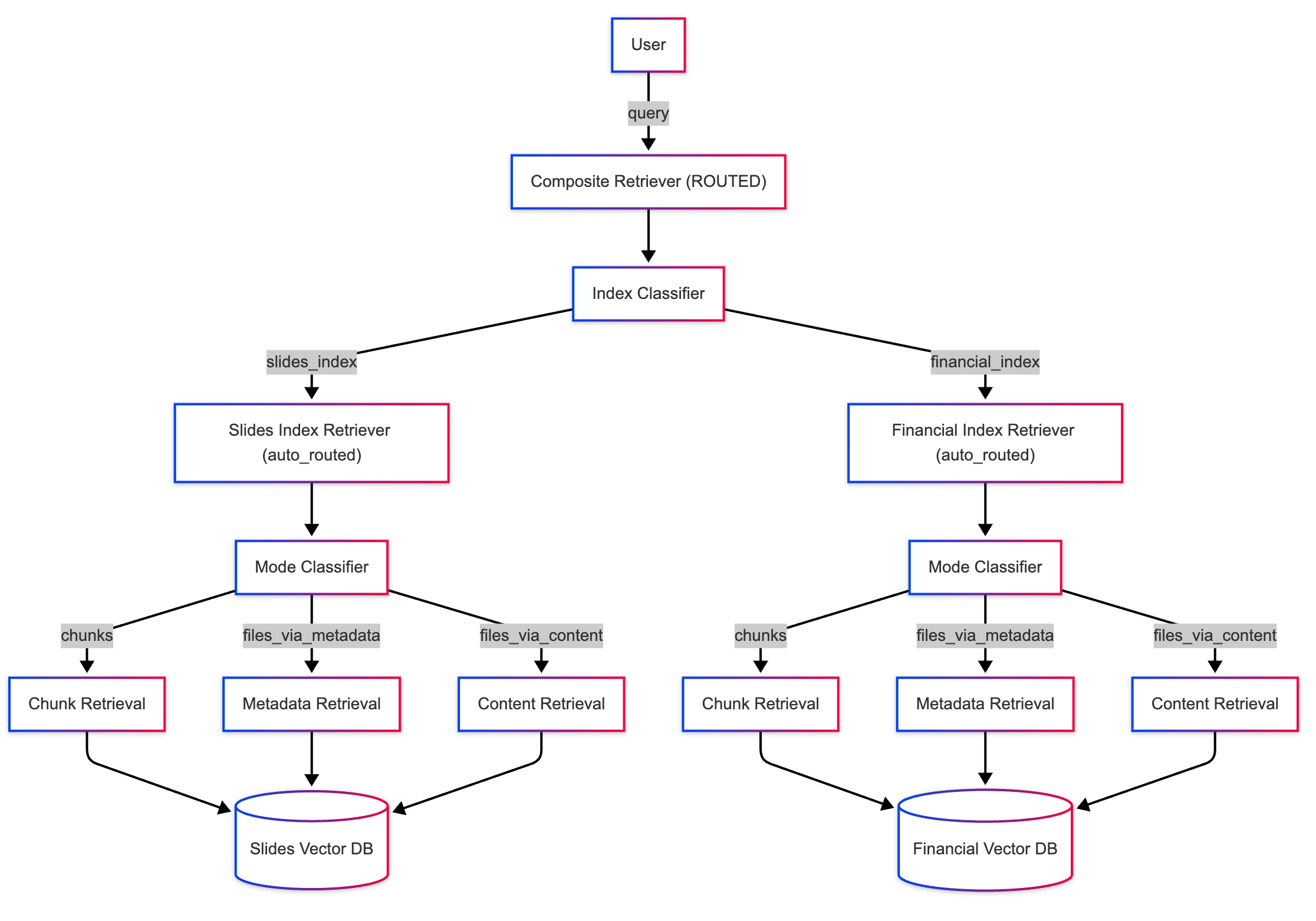
RAG已死,万岁代理检索
Blog on LlamaIndex
·
