
MemEx:用于大型语言模型代理的可编程草稿板
内容提要
MemEx是Databricks开发的一种新工具,旨在解决大型语言模型在处理信息时的上下文限制。通过将工具输出作为Python对象存储,MemEx提高了模型的准确性和效率,尤其在复杂的企业数据检索任务中表现优异。与传统工具调用方法相比,MemEx更好地管理和分析数据,减少错误并降低成本。
关键要点
-
MemEx是Databricks开发的一种新工具,旨在解决大型语言模型在处理信息时的上下文限制。
-
MemEx通过将工具输出作为Python对象存储,提高了模型的准确性和效率,尤其在复杂的企业数据检索任务中表现优异。
-
与传统工具调用方法相比,MemEx更好地管理和分析数据,减少错误并降低成本。
-
MemEx能够处理任意长度的输入,支持审计代理轨迹和多轨迹的并行思考。
-
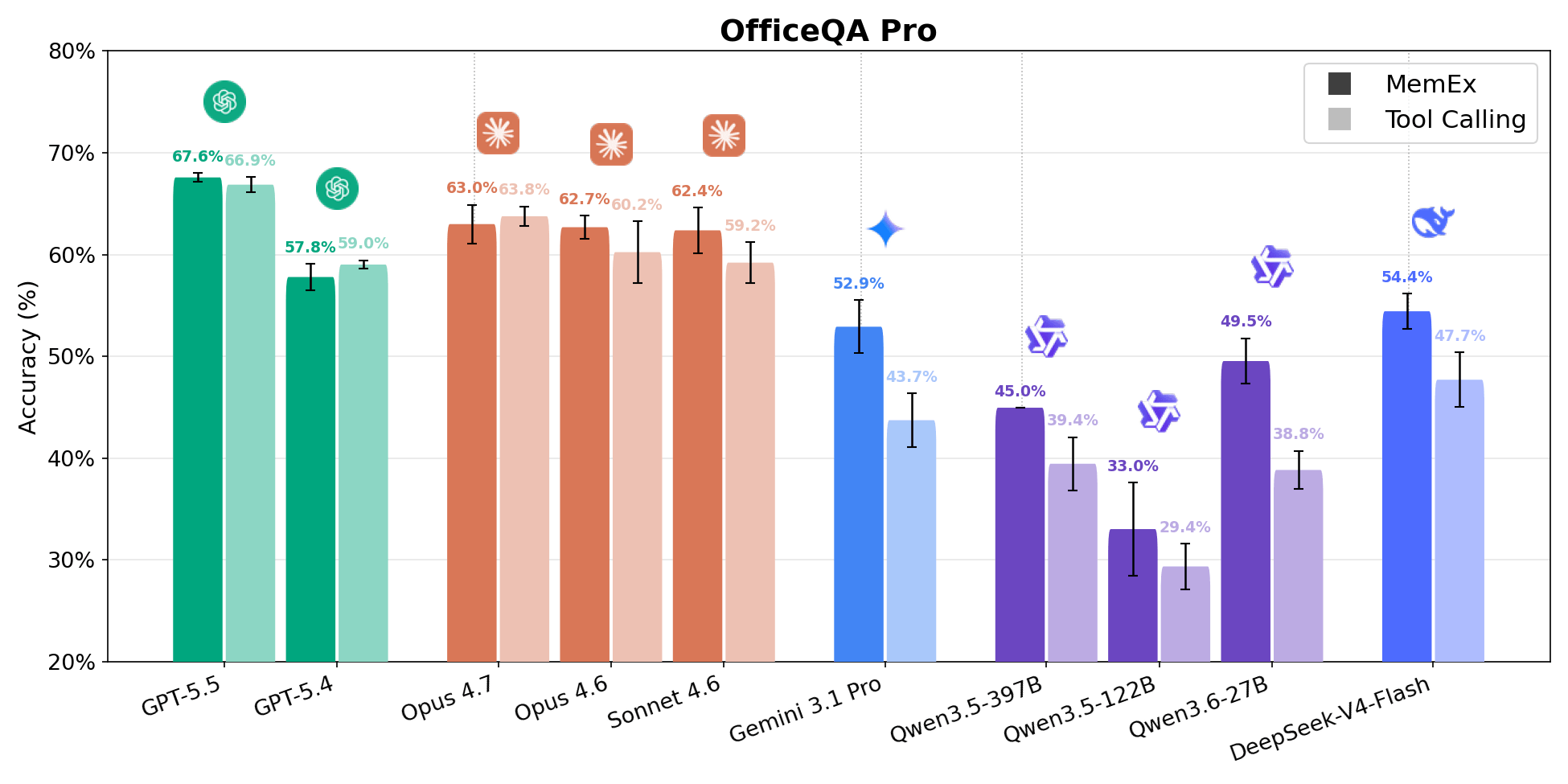
在多个前沿模型的评估中,MemEx在成本和准确性上均优于传统的工具调用方法。
-
MemEx的设计允许在同一代码块中进行多个工具调用,减少了数据传输中的错误和延迟。
-
MemEx的实现基于持久的Python内核,支持跨回合的状态保持和工具自动注入。
-
Databricks计划将MemEx推广到其第一方代理和Agent Factory中,提升用户体验。
延伸解读
MemEx的优势与应用
MemEx通过将工具输出作为Python对象存储,显著提升了大型语言模型在复杂数据检索任务中的准确性和效率。尤其在处理企业数据时,MemEx能够有效管理上下文,减少错误,降低成本。这使得企业在进行数据分析时,能够更快速地获得准确结果,提升决策效率。
与传统工具的比较
与传统的工具调用方法相比,MemEx在处理复杂任务时表现出更高的准确性和更低的成本。传统方法往往需要多次数据传输,容易出现错误,而MemEx通过在同一代码块中进行多次工具调用,减少了数据传输的复杂性,提升了整体效率。
潜在风险与局限性
尽管MemEx在多个模型中表现优异,但其依赖于Python内核的设计可能会限制其在某些环境中的应用。此外,MemEx的性能提升主要体现在特定类型的任务上,对于简单任务,其优势可能不明显。因此,用户在选择使用MemEx时需考虑具体应用场景。
延伸问答
MemEx是什么,它的主要功能是什么?
MemEx是Databricks开发的一种工具,旨在解决大型语言模型在处理信息时的上下文限制,通过将工具输出作为Python对象存储,提高模型的准确性和效率。
MemEx如何提高大型语言模型的效率?
MemEx通过将工具输出作为Python对象存储,允许模型处理任意长度的输入,从而减少错误并降低成本,特别是在复杂的企业数据检索任务中表现优异。
与传统工具调用方法相比,MemEx有哪些优势?
MemEx在管理和分析数据方面表现更好,能够减少错误和降低成本,同时支持多个工具调用在同一代码块中进行,避免了数据传输中的错误和延迟。
MemEx如何支持并行思考和审计代理轨迹?
MemEx能够处理任意长度的输入,支持审计代理轨迹和多轨迹的并行思考,使得模型可以在多个任务中同时进行推理。
Databricks计划如何推广MemEx?
Databricks计划将MemEx推广到其第一方代理和Agent Factory中,以提升用户体验。
MemEx在成本和准确性方面的表现如何?
在多个前沿模型的评估中,MemEx在成本和准确性上均优于传统的工具调用方法,能够显著提高模型的准确性并降低使用成本。
