Go语言强调简单和明确,但近期提案揭示了%q格式化的误用问题,开发者常误用%q处理整数,导致意外输出。Go团队将增强go vet工具以警告此类错误,反映出语言设计的复杂性与历史包袱。
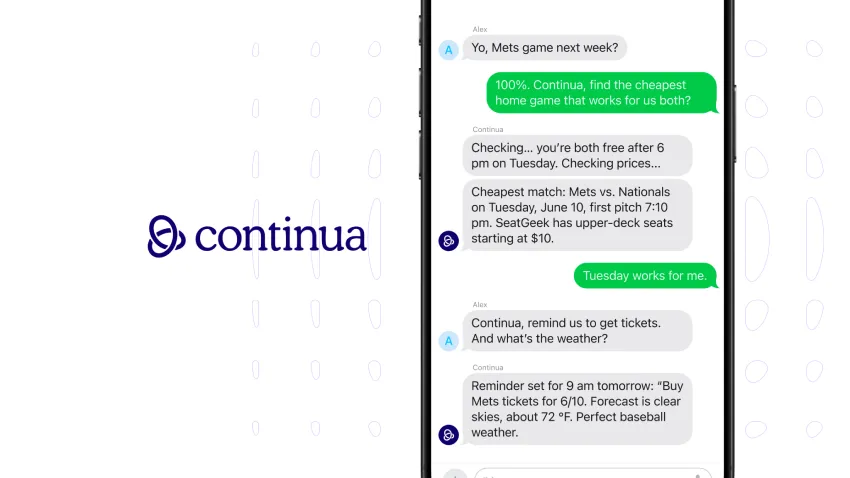
2023年初,David Petrou离开谷歌创办了Continua,利用AI代理提升群聊互动。该公司已获得800万美元融资,目标是通过AI减少群聊混乱,自动设置提醒和生成文档。Petrou指出,让AI自然融入群聊是技术上的挑战。
本文介绍了多个多模态基准测试的开发,包括MM-Vet、MMBench和AlignMMBench,旨在评估大型视觉语言模型(VLMs)在复杂任务中的表现。研究强调了人类偏好的重要性,并推出了WildVision-Arena平台以收集反馈。此外,提出了MMStar和MLLM-Bench,以解决数据泄漏和主观性评估的问题,推动多模态智能的发展。
本研究提出了一种利用一次重复OCT扫描生成OCTA图像的血管提取流程,使用Vasculature Extraction Transformer(VET)实现。VET提取的OCTA图像质量中等,对比度更高,数据采集时间缩短到2秒。VET在处理颈部和面部OCTA数据时优于SV和ED算法。该研究表明,VET能够从快速一次重复的OCT扫描中提取血管图像,有助于准确诊断患者。
该文章介绍了一种基于学习的视可见性面重建方法,使用3D Delaunay四面体化和基于图神经网络的分类方法来识别点云中的缺陷区域并生成表面模型的能量模型。该方法结合了局部几何和视线可见性信息,通过深度学习和能量模型的优点,比当前公开的基于学习和非学习的表面重建算法更优。
该研究提出了一种利用一次重复OCT扫描生成OCTA图像的血管提取流程,使用VET实现。VET提取的OCTA图像具有更高的图像对比度和中等的质量,并将所需数据采集时间缩短到了大约2秒。
完成下面两步后,将自动完成登录并继续当前操作。