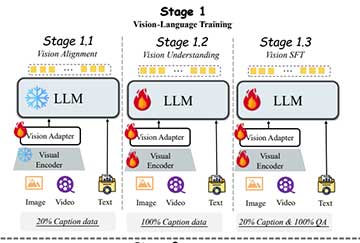
多模态大型语言模型VITA-1.5通过三阶段训练整合视觉、语言和语音,解决模态冲突,提升实时交互能力。与VITA-1.0相比,VITA-1.5采用端到端框架,表现优异,应用潜力广泛。
完成下面两步后,将自动完成登录并继续当前操作。