
VITA-1.5:多模态大语言模型,通过三阶段训练方法整合视觉、语言和语音
原文中文,约1400字,阅读约需4分钟。
📝
内容提要
多模态大型语言模型VITA-1.5通过三阶段训练整合视觉、语言和语音,解决模态冲突,提升实时交互能力。与VITA-1.0相比,VITA-1.5采用端到端框架,表现优异,应用潜力广泛。
🎯
关键要点
-
多模态大型语言模型VITA-1.5通过三阶段训练整合视觉、语言和语音,解决模态冲突。
-
VITA-1.5采用端到端框架,减少延迟并简化交互,提升实时交互能力。
-
模型结合视觉和语音编码器以及语音解码器,实现近乎实时的交互。
-
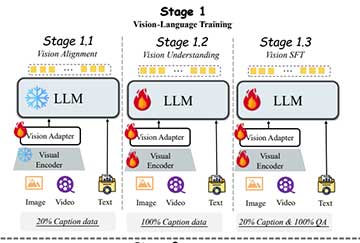
训练过程分为三个阶段:视觉语言训练、音频输入调整和音频输出调整。
-
VITA-1.5在各种基准测试中表现出色,视觉语言能力与领先模型相当。
-
加入音频处理不会损害其视觉推理能力,展现出实际应用潜力。
-
VITA-1.5为多模态集成挑战提供了有效解决方案,推动多模态AI领域的发展。
❓
延伸问答
VITA-1.5模型的主要创新是什么?
VITA-1.5通过三阶段训练整合视觉、语言和语音,采用端到端框架,减少延迟并提升实时交互能力。
VITA-1.5是如何解决模态冲突的?
VITA-1.5通过渐进式多模态训练,结合视觉和音频编码器,确保不同模态之间的有效对齐和处理。
VITA-1.5在基准测试中的表现如何?
VITA-1.5在各种基准测试中表现出色,其视觉语言能力与领先模型相当,且在语音任务中错误率较低。
VITA-1.5的训练过程分为哪几个阶段?
训练过程分为视觉语言训练、音频输入调整和音频输出调整三个阶段。
VITA-1.5的开源可用性有什么意义?
VITA-1.5的开源可用性促进了研究人员和开发者的创新,推动了多模态AI领域的发展。
VITA-1.5如何提升实时交互能力?
VITA-1.5通过端到端框架和结合视觉、语音编码器,减少了交互延迟,实现近乎实时的交互。
🏷️
