本文提出了一种新颖的端到端框架,结合ResNet和视觉变换器,利用可变形卷积等先进技术,显著提升自然图像的文本识别性能。实验结果表明,该框架在多个数据集上表现优异。
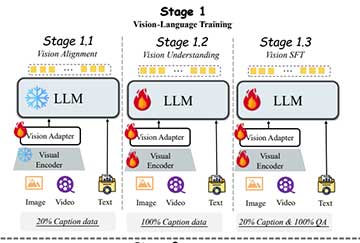
多模态大型语言模型VITA-1.5通过三阶段训练整合视觉、语言和语音,解决模态冲突,提升实时交互能力。与VITA-1.0相比,VITA-1.5采用端到端框架,表现优异,应用潜力广泛。
本文使用预训练序列到序列模型BART,通过生成式公式解决所有ABSA子任务,实现了统一的端到端框架。实验结果表明,在四个ABSA数据集上实现了实质性的性能提升。
Map Transformer是一种用于在线矢量高清地图构建的端到端框架,能够处理任意形状的地图元素,并在nuScenes和Argoverse2数据集上达到最先进的性能。代码和演示可在https://github.com/hustvl/MapTR中找到。
该研究使用端到端框架生成医学报告,准确性高且语言流畅。提供附加信息可显著提高性能。
ED-Pose是一种新型的端到端框架,用于多人姿态估计,具有明确的框检测技术。该方法将全局和局部信息进行上下文学习,并解决了两个显式框检测过程,不需要后期处理和密集热图监督。该方法在有效性和效率方面比两阶段和单阶段方法更优。
本文提出了一个使用强化学习解决车辆路径问题的端到端框架。通过训练一个单一模型,模型能够实时生成近最优解决方案,无需重新训练。方法在解决负载容量VRP中优于启发式算法和Google的OR-Tools,同时计算时间可比。框架适用于其他VRP变体和组合优化问题。
通过跨视频上下文知识,提出了一种改善细粒度行动模式理解的新方法,并减少模糊性。通过端到端框架,在多个数据集上表现优于最先进方法。
本文介绍了一种用于解析羽毛球比赛直播录像中球员移动的端到端框架。通过可视化输入和仅使用视觉线索,计算球员在球场上的移动距离,并移除重播和冗余部分,聚焦于比赛过程。通过对每一帧进行球员追踪,计算每位球员的移动距离和平均速度,并绘制热力图以分析比赛过程。
本文提出了一个以神经网络为基础的端到端框架,用于解决在线多目标跟踪中的数据关联问题。算法将帧间数据关联建模成最大带权二分匹配问题,并利用预先学习好的神经网络进行求解,该网络结合了外观和运动特征来计算有关联所需的邻接矩阵。实验表明,该框架能够提供更快的计算速度和更好的跟踪精度。
本文提出了一个新颖的端到端框架,用于从单眼图像或序列中估计三维手部姿势。通过使用扩散模型和正向运动学层,生成的姿势符合实际。通过添加Transformer模块,克服了抖动问题。该方法在不同数据集上展示了领先的鲁棒性、泛化性和准确性。
DeepTransport是一种端到端框架,利用卷积神经网络和循环神经网络获取传输网络拓扑内的时空交通信息,并引入注意力机制对齐空间和时间信息。该方法构建并发布了实时大规模交通状况数据集,并在实验证明在时空领域捕捉了复杂的关系,相对于传统的统计方法和最先进的深度学习方法,取得了显著的性能提升。
完成下面两步后,将自动完成登录并继续当前操作。