本研究提出了一种新的多粒度手势生成框架M3G,解决了基于音频生成全身人类手势时粒度固定的问题。M3G利用多粒度VQ-VAE技术,能够以不同时间粒度标记和重建运动模式,实验结果表明其在生成自然、富有表现力的全身手势方面优于现有方法。
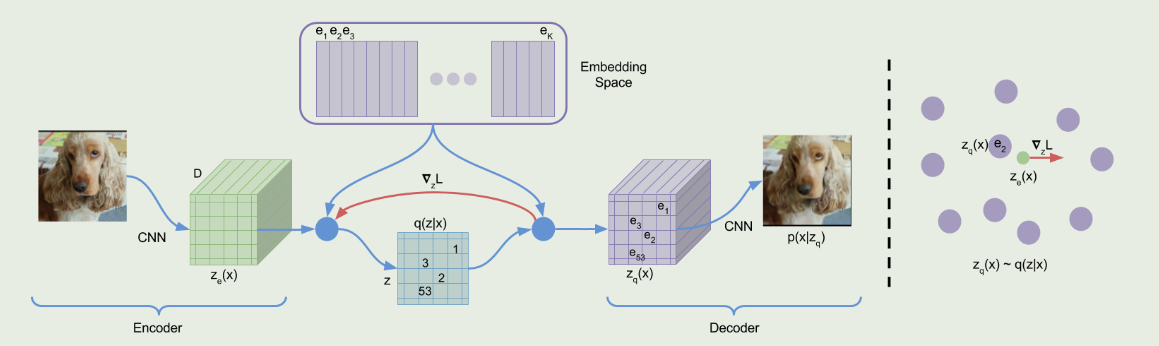
VQVAE是一种无监督学习的离散表征方法,结合了自回归模型和生成模型的优点。通过设计离散字典和直通估计器,VQVAE有效建模离散数据,核心在于向量量化和EMA更新字典,支持多尺度特征提取,提升生成效果。
本文探讨了基于VQ-VAE和GPT的人体运动生成框架,提出了InterGen、CHOIS和HOI-DM等方法,以提高生成质量和多样性。研究表明,通过文本指令生成逼真的人-物互动动作,显著改善了在机器人、游戏和动画等领域的应用效果。
传统深度学习中,VQ-VAE通过向量量化解决潜在变量被忽略的问题,编码器输出离散编码,并结合自监督学习。模型定义离散潜在空间,通过最近邻查找计算潜变量。损失由重构损失和嵌入优化组成。Transformer结合CNN用于高分辨率图像合成,生成过程可控。
本文提出了一种自适应行动量化方案,利用 VQ-VAE 学习状态条件的行动量化,解决了行动空间的指数爆炸问题。在复杂机器人操作任务中,通过离线强化学习算法实现了性能提升,特别是在 Robomimic 环境中,离散化方法相比于连续方法提高了 2-3 倍的效率。
本文研究了基于 VQ-VAE 和 GPT 的人体运动生成框架,提出了多种提升生成质量的方法,包括运动检索、文本生成评估和无监督学习。通过创新模型和数据集,展示了在复杂文本描述下生成高质量、丰富多样的3D动作序列的能力,尤其在 HumanML3D 和 KIT-ML 数据集上表现优异。
德国海德堡大学IWR团队发表了整合VQVAE和GAN的VQGAN模型,使用Transformer合成高分辨率图像,并提供了代码实现。
该文章介绍了一种多阶段、多码本的高效神经TTS合成方法,使用VQ-VAE编码语音训练数据的Mel频谱图,并通过多阶段逐渐下采样,将其量化为多个具有不同时间分辨率的MSMC表示。神经声码器将预测的MSMCR转换为最终语音波形。实验证明,该方法在英语TTS数据库中性能优于基准值,同时低参数的紧凑版本也能保持高性能。
本文介绍了优先级中心的M2DM模型,利用基于Transformer的VQ-VAE得出离散的动作表示。该模型通过自注意机制和正则化项抵消代码坍塌,并采用噪声调度方式确定动作标记的重要性。实验证实该模型在保真度和多样性方面超过现有技术,尤其对于复杂的文本描述。
本文介绍了一种优先级中心的M2DM模型,利用基于Transformer的VQ-VAE得出离散的动作表示。该模型通过自注意机制和正则化项抵消代码坍塌,并采用噪声调度方式确定动作标记的重要性。实验证实该模型在保真度和多样性方面超过现有技术,尤其对于复杂的文本描述。
本文提出了一种增强 VQ-VAE 结构的频率补全模块和动态频谱损失,用于平衡频率以获得最佳重建。FA-VAE 进一步扩展到文本到图像合成任务中,并提出了交叉注意力自回归变换器以获得更精确的文本语义属性。实验结果表明,FA-VAE 能够更忠实地恢复细节,CAT 在图像文本语义对齐方面也显示出更好的生成质量。
本文介绍了一种基于 Transformer 的 VQ-VAE 的优先级中心的 M2DM 模型,用于逆扩散过程中的动作表示。该模型在保真度和多样性方面超过了现有技术,尤其对于复杂的文本描述。
本文介绍了一种基于 Transformer 的 VQ-VAE 模型,用于逆扩散过程中的动作表示。该模型在保真度和多样性方面超过了现有技术,尤其对于复杂的文本描述。
完成下面两步后,将自动完成登录并继续当前操作。