
回看深度学习:经典网络学习
原文中文,约4500字,阅读约需11分钟。
📝
内容提要
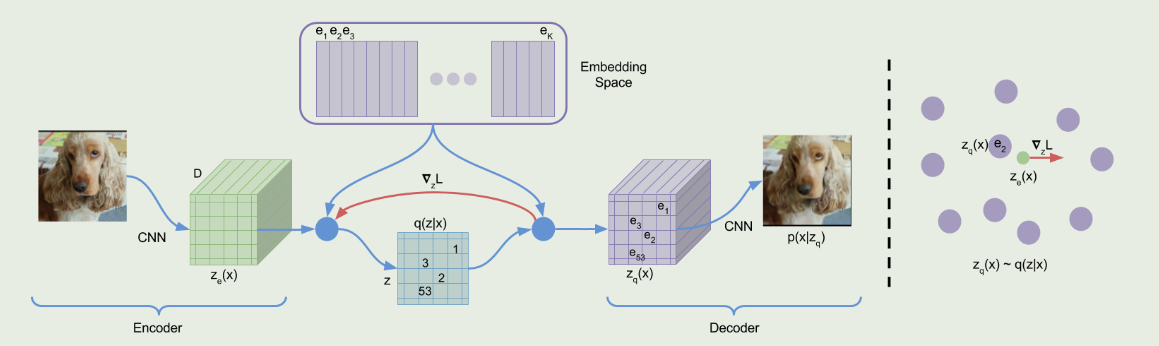
传统深度学习中,VQ-VAE通过向量量化解决潜在变量被忽略的问题,编码器输出离散编码,并结合自监督学习。模型定义离散潜在空间,通过最近邻查找计算潜变量。损失由重构损失和嵌入优化组成。Transformer结合CNN用于高分辨率图像合成,生成过程可控。
🎯
关键要点
-
传统深度学习中,VQ-VAE通过向量量化解决潜在变量被忽略的问题。
-
VQ-VAE的编码器输出离散编码,结合自监督学习。
-
模型定义离散潜在空间,通过最近邻查找计算潜变量。
-
损失由重构损失和嵌入优化组成。
-
Transformer结合CNN用于高分辨率图像合成,生成过程可控。
-
VQ-VAE避免了后验崩溃问题,学习离散潜在表示。
-
模型通过共享嵌入空间计算离散潜变量,并优化重构损失。
-
使用向量量化算法优化嵌入空间,确保嵌入训练速度与编码器参数相匹配。
-
Transformer在图像生成中结合卷积神经网络的优点,提升表达能力。
-
生成高分辨率图像需要处理图像块和裁剪图像,使用滑动窗口方式进行采样。
❓
延伸问答
VQ-VAE是如何解决潜在变量被忽略的问题的?
VQ-VAE通过向量量化的方法,使编码器输出离散编码,从而避免潜在变量被忽略的问题。
VQ-VAE的损失函数由哪些部分组成?
VQ-VAE的损失函数由重构损失和嵌入优化组成,分别用于优化解码器和编码器。
Transformer如何与CNN结合用于高分辨率图像合成?
Transformer结合CNN的优点,通过学习表示的离散码本,能够有效合成高分辨率图像。
VQ-VAE如何避免后验崩溃问题?
VQ-VAE通过使用向量量化方法,使潜在变量与解码器配对时不被忽略,从而避免后验崩溃问题。
在生成高分辨率图像时需要处理哪些技术细节?
生成高分辨率图像时,需要对图像块和裁剪图像进行处理,并使用滑动窗口方式进行采样。
VQ-VAE的编码器输出是什么?
VQ-VAE的编码器输出是离散编码,这些编码用于表示输入数据的潜在特征。
🏷️
