

人工智能正在改变客户对数据库的需求。MongoDB 8.3应运而生
MongoDB
·
PSMDB沙箱:基于浏览器的UI,用于通过Terraform和Ansible部署MongoDB
Percona Database Performance Blog
·

TimescaleDB如何在LogTide的可观察性平台中超越ClickHouse和MongoDB
Timescale Blog
·
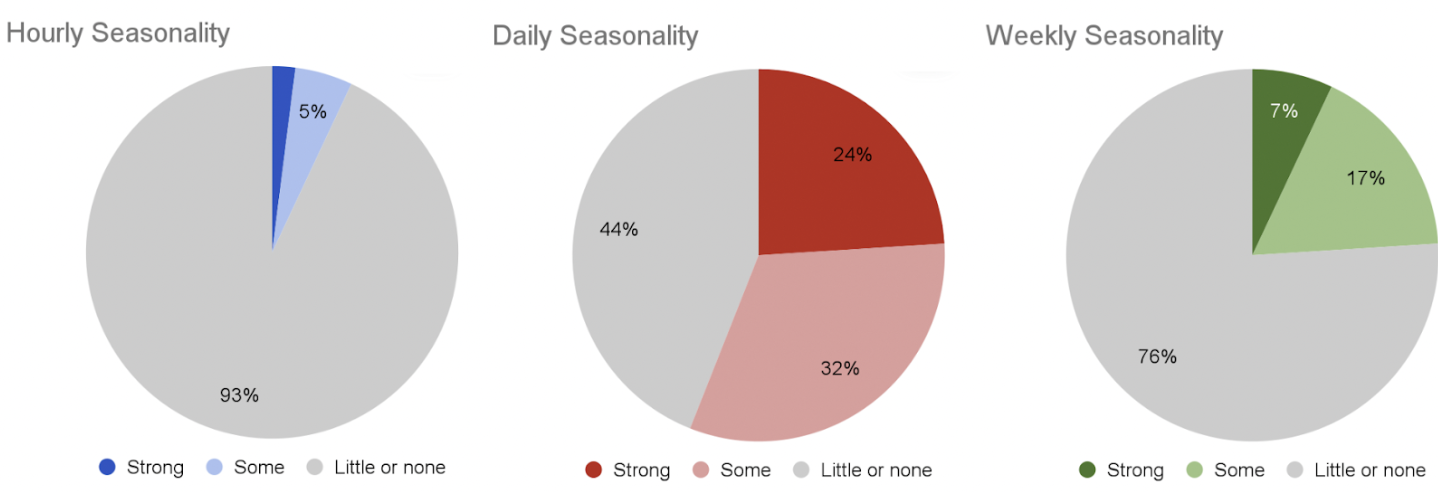
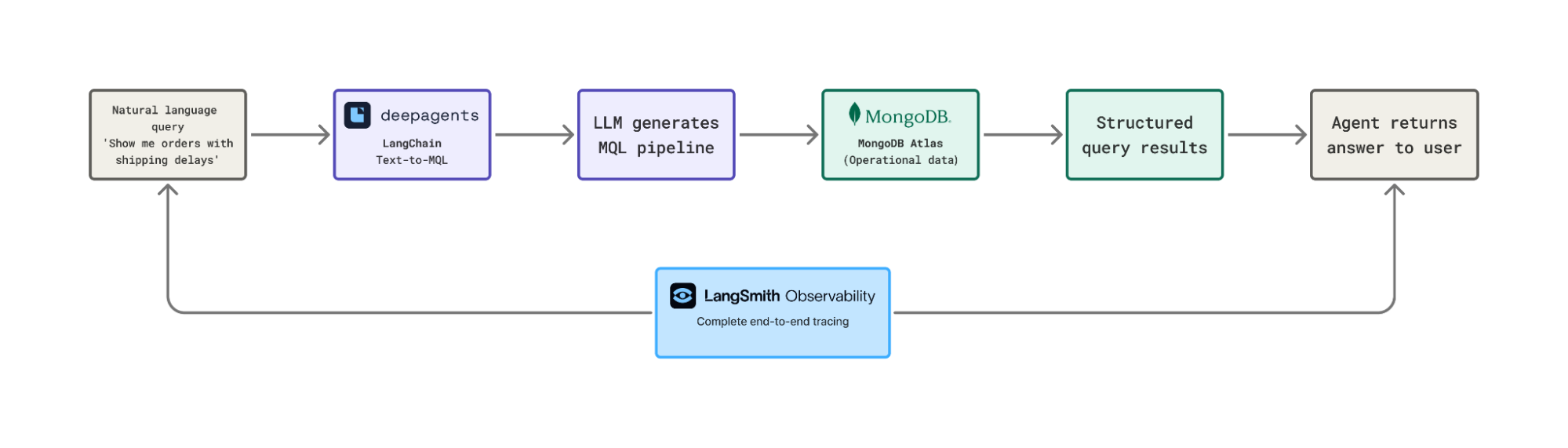
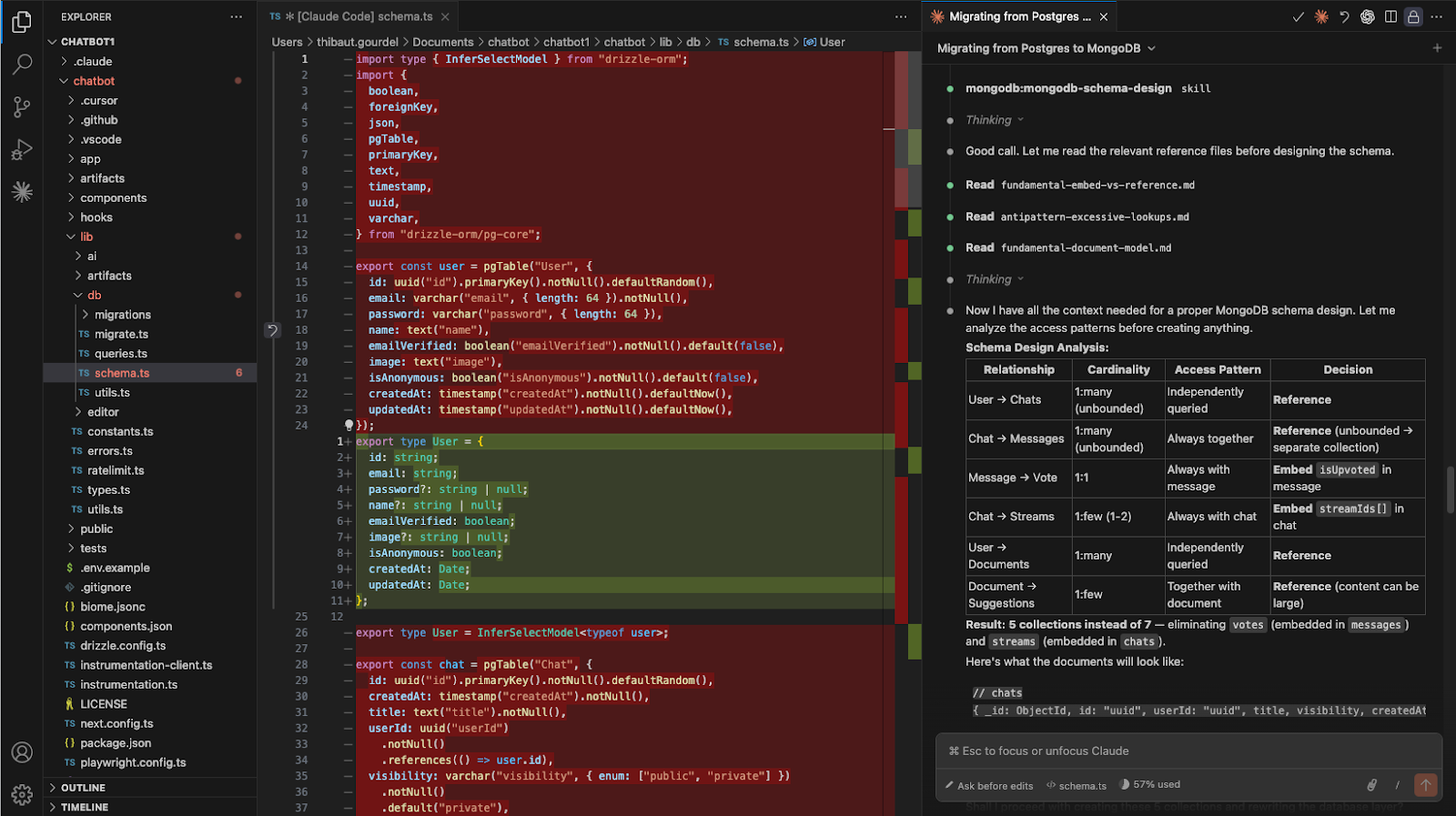
介绍MongoDB代理技能和插件,用于编码代理
MongoDB
·

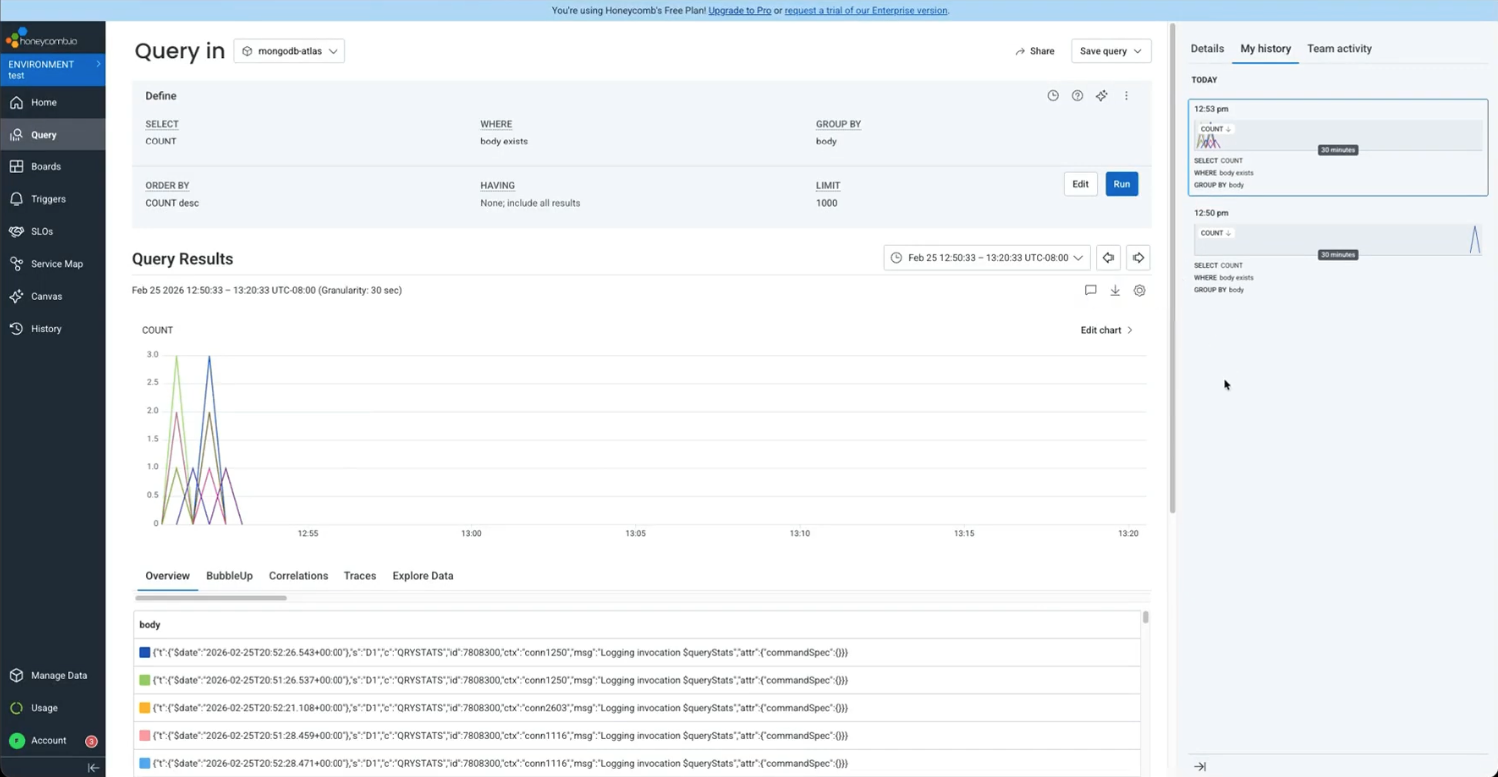
可观察性与OpenTelemetry:MongoDB Atlas日志集成介绍
MongoDB
·

走进MongoDB都柏林:我们国际增长的核心
MongoDB
·

与MongoDB的创新 | 客户成功案例,2026年2月
MongoDB
·
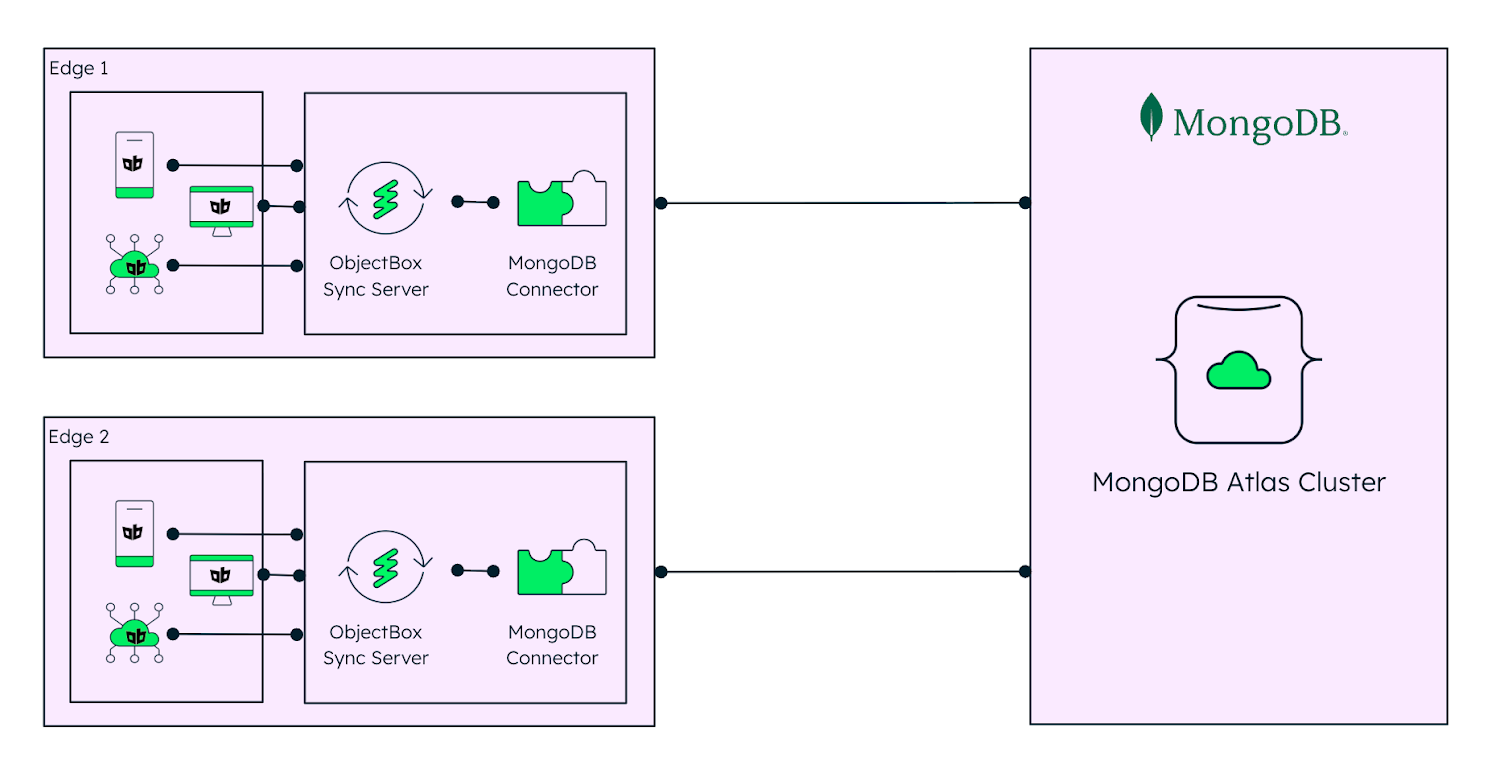
边缘AI轻松实现:MongoDB与ObjectBox的数据同步
MongoDB
·
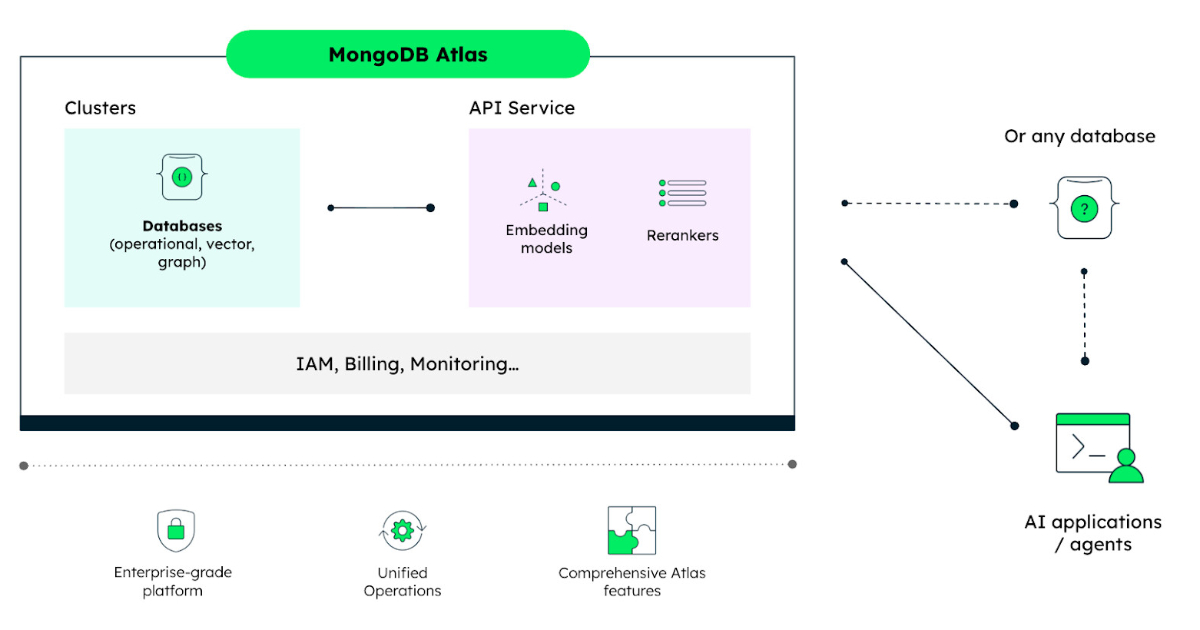
.png)
MongoDB.local 旧金山 2026:更快交付生产级 AI
MongoDB
·
