
AGUVIS:一种统一的纯视觉框架,可跨平台转变自主 GUI 交互
内容提要
AGUVIS框架通过纯视觉输入解决了GUI自动化的关键挑战,消除了对文本表示的依赖,提升了跨平台的泛化能力。该模型在基础和推理阶段有效结合,显著提高了任务执行的准确性和效率,成为首个完全自主的视觉智能体。
关键要点
-
AGUVIS框架通过纯视觉输入解决了GUI自动化的关键挑战,消除了对文本表示的依赖。
-
该模型提升了跨平台的泛化能力,能够有效处理不同平台的视觉布局和交互逻辑。
-
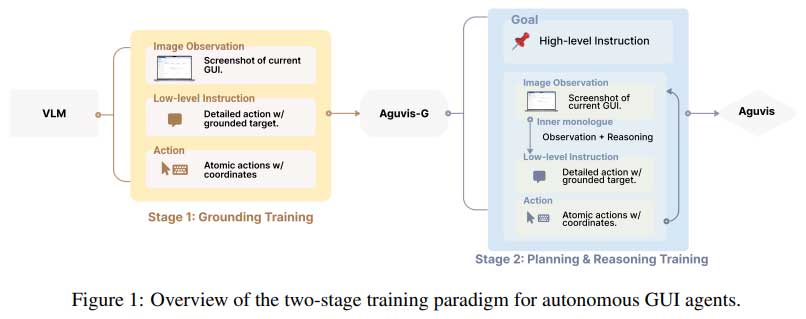
AGUVIS采用两阶段训练范式,结合基础和推理能力,提高任务执行的准确性和效率。
-
第一阶段专注于将自然语言指令与GUI环境中的视觉元素进行绑定和映射。
-
第二阶段引入规划和推理,训练模型在各种平台和场景中执行多步骤任务。
-
AGUVIS在GUI基础测试中表现出色,平均准确率达到89.2%,超越了现有方法。
-
该模型的推理成本降低了93%,为GUI自动化树立了新标杆。
-
AGUVIS使用基于图像的输入,大大降低了代币成本,使模型与GUI的视觉特性保持一致。
-
该框架的模块化架构允许无缝适应新环境和任务,支持多模态推理和基础研究。
-
AGUVIS在Web、移动和桌面平台上均取得了显著的准确率和效率成果。
延伸解读
AGUVIS的创新优势
AGUVIS框架通过纯视觉输入消除了对文本表示的依赖,这一创新使得模型能够更好地理解和处理GUI的视觉特性。相比传统方法,AGUVIS在跨平台的泛化能力上表现优异,能够有效应对不同平台的视觉布局和交互逻辑,提升了自动化的准确性和效率。
两阶段训练的意义
AGUVIS采用的两阶段训练范式,首先将自然语言指令与视觉元素绑定,随后引入规划和推理,显著提高了模型在复杂任务中的表现。这种方法不仅提升了训练效率,还增强了模型在多步骤任务中的执行能力,为自主GUI交互提供了更为强大的支持。
降低推理成本的影响
AGUVIS在推理成本上实现了93%的降低,这一成就为GUI自动化领域树立了新标杆。通过减少代币成本,AGUVIS使得模型在处理复杂任务时更加高效,降低了资源消耗,为实际应用提供了更具经济性的解决方案。
延伸问答
AGUVIS框架的主要功能是什么?
AGUVIS框架通过纯视觉输入解决GUI自动化的关键挑战,消除了对文本表示的依赖,提升了跨平台的泛化能力。
AGUVIS是如何提高任务执行的准确性和效率的?
AGUVIS采用两阶段训练范式,结合基础和推理能力,从而显著提高任务执行的准确性和效率。
AGUVIS在不同平台上的表现如何?
AGUVIS在Web、移动和桌面平台上均取得了显著的准确率,Web平台准确率达88.3%,移动端85.7%,桌面端81.8%。
AGUVIS框架的推理成本相比其他模型如何?
AGUVIS的推理成本降低了93%,为GUI自动化树立了新标杆。
AGUVIS如何处理自然语言指令与GUI元素的关系?
AGUVIS在第一阶段专注于将自然语言指令与GUI环境中的视觉元素进行绑定和映射。
AGUVIS的模块化架构有什么优势?
AGUVIS的模块化架构允许无缝适应新环境和任务,支持多模态推理和基础研究。
