本研究采用深度强化学习和近端策略优化算法,成功训练出能够通过视觉输入实现专业圈速的赛车驾驶代理,有效解决了紧急情况下的轮胎抓地力控制问题。
该研究提出了一种新的分布式交叉注意力机制LV-XAttn,旨在解决多模态大语言模型在处理大量视觉输入时的高内存需求和通信开销问题。该方法通过在每个GPU上保留大的键值块并交换较小的查询块,显著降低了通信开销,并支持更长的视觉上下文,实验证明可实现高达5.58倍的速度提升。
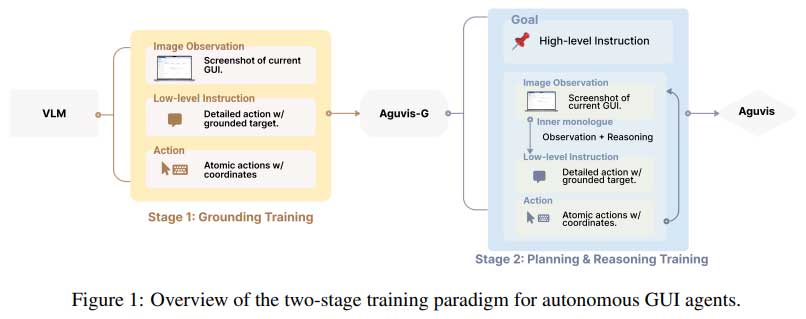
AGUVIS框架通过纯视觉输入解决了GUI自动化的关键挑战,消除了对文本表示的依赖,提升了跨平台的泛化能力。该模型在基础和推理阶段有效结合,显著提高了任务执行的准确性和效率,成为首个完全自主的视觉智能体。
本研究结合模型控制与强化学习,开发了四足机器人(Unitree Laikago)的鲁棒控制器。通过基于扭矩的强化学习,机器人在复杂地形上展现出更高的能效和抗干扰能力,并提出了整体控制策略以解决四肢协调问题,利用视觉输入实现移动操纵。研究结果表明机器人在多种地形下具备灵活运动和高效任务完成能力。
本研究探讨了多模态大型语言模型(MLLMs)评估中的问题,强调视觉输入的重要性。通过改进评估协议和自动知识识别技术,研究发现知识增强管道显著提升了性能,揭示了LLM在MLLM中的关键作用。
本文探讨了在室内环境中通过视觉输入主动接近物体的通用行动策略,提出了GAPLE解决方案,并在House3D数据集及真实场景中进行了验证。研究涉及无监督视觉深度学习、单目深度估计和元学习方法,旨在提升室内单张图像深度预测的泛化能力,开发了Meta Omnium数据集和G2-MonoDepth基准测试,展示了在深度估计中的优越性能。
本文讨论了在大型语言模型中引入视觉的趋势,指出了高维视觉输入空间本质上是对抗性攻击的理想介质,以及这种趋势的广泛功能使得视觉攻击者有更多的攻击目标。研究发现对抗性例子可以打破安全机制并生成有害内容,因此强调了对于安全使用视觉语言模型的紧迫需要,需要进行全面的风险评估,强大的防御措施和实施负责任的工作实践。
完成下面两步后,将自动完成登录并继续当前操作。