
大规模数据质量监控与自主AI
内容提要
随着数据和AI产品的增加,维护数据质量变得更加困难。传统方法无法满足规模化需求,导致许多数据未被监控。Databricks推出的AI驱动数据质量监控,能够自动识别异常,持续监控数据,提高数据可信度和完整性。
关键要点
-
随着数据和AI产品的增加,维护数据质量变得更加困难。
-
传统的数据质量方法无法满足规模化需求,导致许多数据未被监控。
-
Databricks推出的AI驱动数据质量监控,能够自动识别异常并持续监控数据。
-
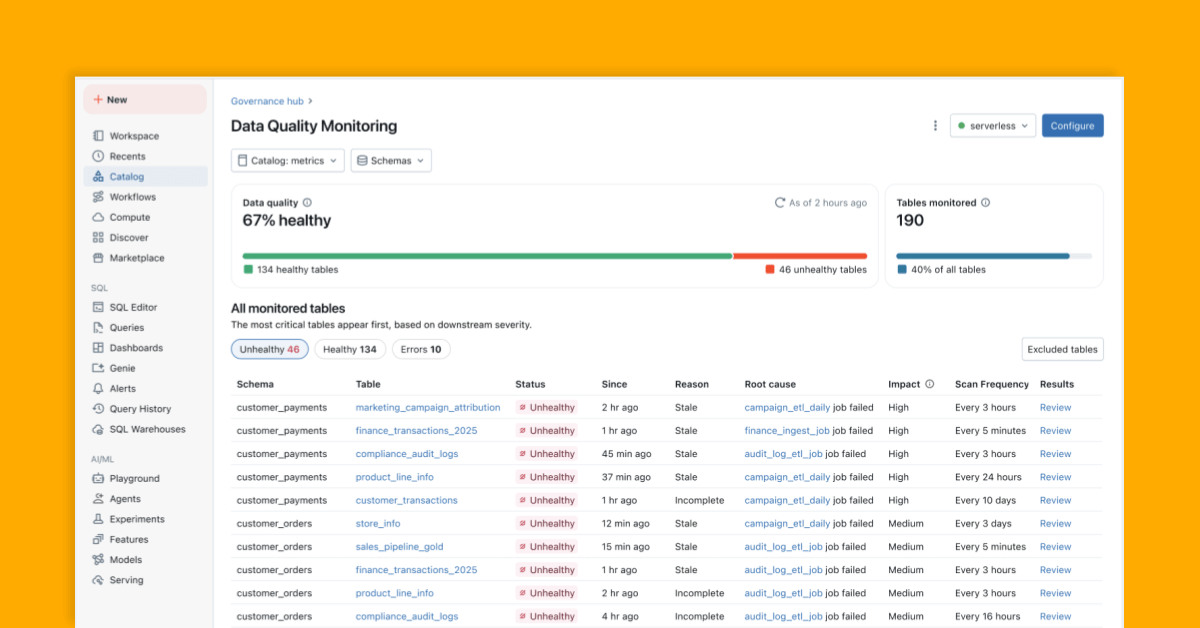
数据质量监控取代了分散的手动检查,采用了适应性强的AI代理方法。
-
深度集成Databricks平台,能够直接在上游Lakeflow作业和管道中显示根本原因。
-
通过Unity Catalog的血缘和认证标签优先处理高影响数据集。
-
数据质量监控通过异常检测和数据分析提供可操作的洞察。
-
异常检测在模式层面启用,无需手动配置,AI代理学习历史模式以识别意外变化。
-
数据分析在表层面启用,捕获摘要统计信息并跟踪其随时间的变化。
延伸解读
数据质量监控的重要性
随着企业数据量的激增,数据质量监控变得尤为重要。传统方法无法满足大规模数据的需求,导致许多数据未被有效监控。Databricks的AI驱动监控能够实时识别异常,帮助企业在快速变化的环境中保持数据的可信度和完整性。
AI代理的优势
Databricks采用的AI代理方法,能够自动学习历史数据模式并适应变化,避免了手动配置的繁琐。这种方法不仅提高了监控的效率,还能及时发现潜在问题,确保关键数据集的健康状态。
优先处理高影响数据集
通过Unity Catalog的血缘和认证标签,Databricks能够优先处理对业务影响最大的高风险数据集。这种策略确保了资源的有效利用,使团队能够集中精力解决最重要的问题,从而提升整体数据管理效率。
延伸问答
为什么维护数据质量变得更加困难?
随着数据和AI产品的增加,维护数据质量变得更加困难,传统方法无法满足规模化需求,导致许多数据未被监控。
Databricks的AI驱动数据质量监控有什么优势?
Databricks的AI驱动数据质量监控能够自动识别异常,持续监控数据,提高数据可信度和完整性,取代了分散的手动检查。
异常检测是如何工作的?
异常检测在模式层面启用,AI代理学习历史模式以识别意外变化,无需手动配置,能够监控所有关键表。
如何优先处理高影响数据集?
通过Unity Catalog的血缘和认证标签,数据质量监控能够优先处理高影响数据集,确保重要数据得到及时关注。
数据质量监控如何提供可操作的洞察?
数据质量监控通过异常检测和数据分析提供可操作的洞察,帮助团队更早发现问题并快速解决。
数据分析在数据质量监控中起什么作用?
数据分析在表层面启用,捕获摘要统计信息并跟踪其随时间的变化,为异常检测提供历史背景。
