
用“分区”来面对超大数据集和超大吞吐量
内容提要
分区(sharding)通过将数据分散到多个节点来提升系统可伸缩性,避免热点和数据倾斜。常用的分区方法包括键值范围和散列分区。为消除热点,可以在主键后添加随机数。分区再平衡确保负载均匀,支持手动或自动执行。请求路由需解决服务发现问题,通常使用协调服务(如Zookeeper)跟踪数据分配的变化。
关键要点
-
分区(sharding)通过将数据分散到多个节点来提升系统可伸缩性,避免热点和数据倾斜。
-
分区通常与复制结合使用,确保每个分区的副本存储在多个节点上以保证高可用性。
-
一致前缀读确保因果相关的写入在相同的分区,以避免因复制延迟导致的混乱。
-
分区的目的是将数据和负载均匀分布到各个节点,避免偏斜和热点。
-
根据键值范围进行分区可能导致数据偏斜,需要根据实际情况调整分区边界。
-
散列分区可以均匀分布数据,但不利于高效的范围查询。
-
热点消除可以通过在主键后添加随机数来实现,从而将请求分散到不同的分区。
-
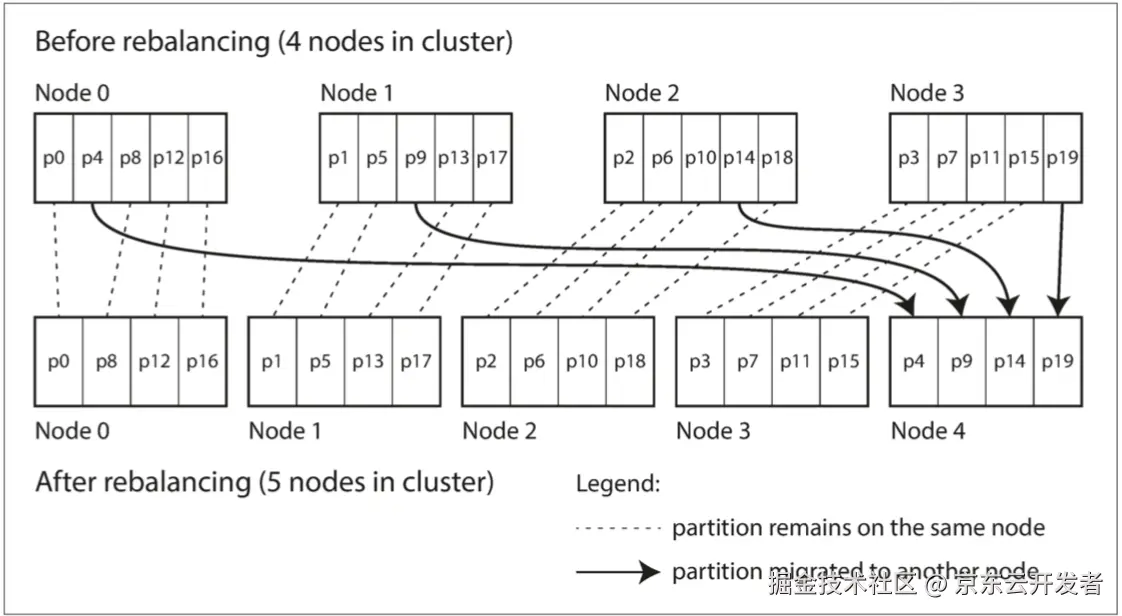
分区再平衡是将负载从一个节点移动到另一个节点的过程,确保数据库在再平衡期间继续接受请求。
-
再平衡可以手动或自动执行,自动再平衡可能导致网络开销和性能下降。
-
请求路由是服务发现的问题,可以通过协调服务(如Zookeeper)跟踪数据分配的变化。
延伸解读
分区的重要性与挑战
分区(sharding)是处理超大数据集和高吞吐量的关键技术,能够有效提升系统的可伸缩性。然而,分区不当可能导致数据偏斜和热点问题,影响系统性能。因此,在设计分区策略时,需要充分考虑数据的分布特性,确保负载均匀分配。
再平衡的复杂性
分区再平衡是确保系统高可用性的重要过程,但其实施可能带来网络开销和性能下降的风险。手动再平衡虽然可控,但需要运维人员的参与;而自动再平衡则可能在不确定的情况下影响用户体验。因此,选择合适的再平衡策略至关重要。
请求路由的解决方案
在分区后,如何高效地找到数据所在节点是一个挑战。使用协调服务(如Zookeeper)可以有效跟踪数据分配变化,确保请求路由的准确性。然而,这也增加了系统的复杂性,需权衡实现的复杂度与系统的灵活性。
延伸问答
分区的主要目的是什么?
分区的主要目的是将数据和负载均匀分布到各个节点上,避免数据偏斜和热点。
如何避免分区中的热点问题?
可以通过在主键后添加随机数来消除热点,从而将请求分散到不同的分区。
分区再平衡的过程是怎样的?
分区再平衡是将负载从一个节点移动到另一个节点的过程,确保数据库在再平衡期间继续接受请求。
什么是请求路由,如何解决服务发现问题?
请求路由是服务发现的问题,可以通过协调服务(如Zookeeper)跟踪数据分配的变化来解决。
分区方法有哪些?
常用的分区方法包括键值范围分区和散列分区。
散列分区的优缺点是什么?
散列分区可以均匀分布数据,但不利于高效的范围查询。
