Microsoft Orleans通过集群架构和容灾机制,实现可伸缩性和容错性。Orleans集群由多个Silo组成,具备弹性扩展、高可用性和负载均衡。故障检测采用心跳机制,Grain可自动恢复,确保业务连续性。
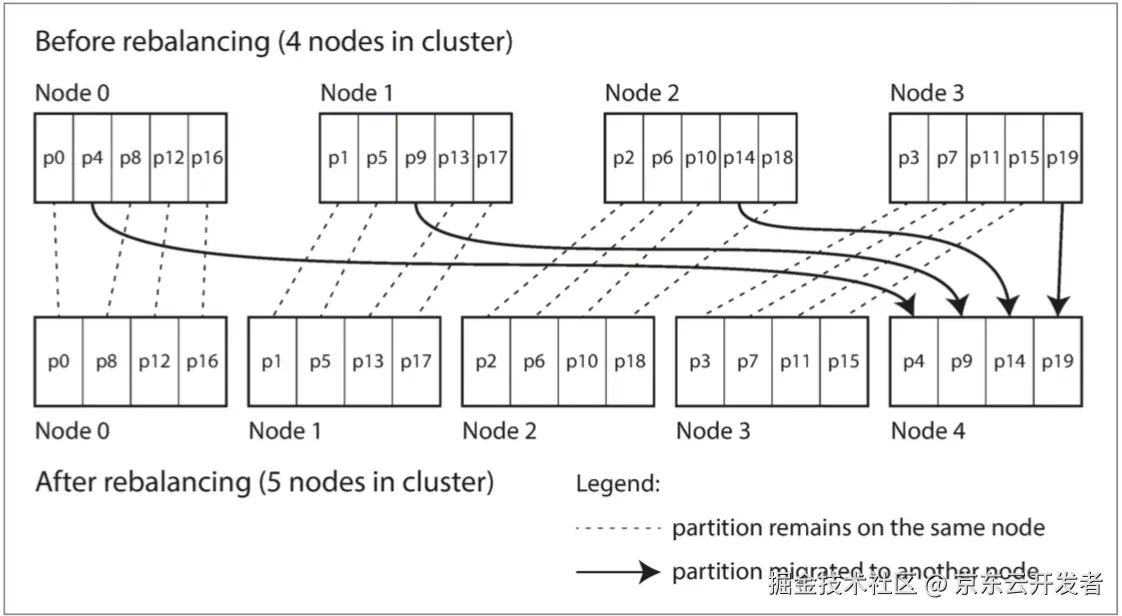
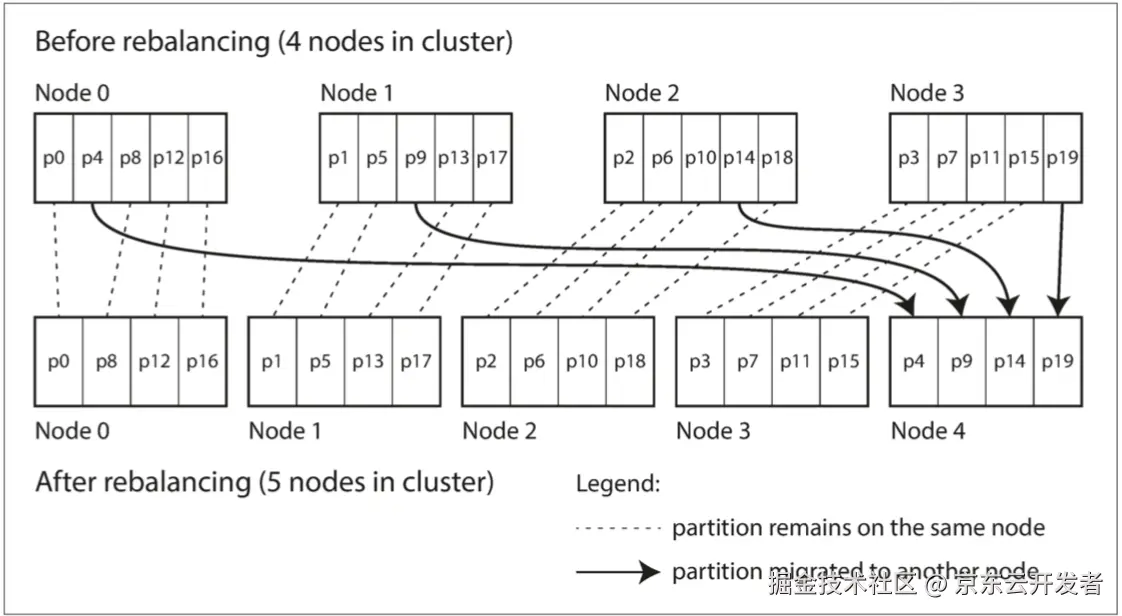
分区(sharding)通过将数据均匀分布在多个节点上,提高系统可伸缩性,避免热点和数据倾斜。为确保一致前缀读,需将因果相关的写入放在同一分区。可通过散列分区和在主键后加随机数来缓解热点问题。分区再平衡可手动或自动执行,以确保负载均匀分配。请求路由需解决服务发现问题,可通过协调服务(如Zookeeper)跟踪数据分配变化。
分区(sharding)通过将数据分散到多个节点来提升系统可伸缩性,避免热点和数据倾斜。常用的分区方法包括键值范围和散列分区。为消除热点,可以在主键后添加随机数。分区再平衡确保负载均匀,支持手动或自动执行。请求路由需解决服务发现问题,通常使用协调服务(如Zookeeper)跟踪数据分配的变化。
本文介绍了Go语言的并发调度系统,分析了其设计目标、挑战及实现过程,旨在帮助开发者深入理解调度器的原理与决策。该专栏包含三篇文章,涉及goroutine设计、可伸缩性及调度艺术,适合希望提升技术深度的读者。
CSS Flexbox是一种高效的布局模型,支持在容器内灵活排列和对齐元素,适合响应式设计。其主要优点包括精确定位和可伸缩性,关键属性有flex容器、flex项目、方向和对齐等。
文章讨论了如何在EC2上部署FastAPI,并启用自动扩展功能,以提高应用的可伸缩性和性能。
本文介绍了13个Kubernetes技巧,包括PreStop钩子、自动密钥轮换、短暂容器调试、水平Pod自动缩放、初始化容器、节点亲和性、污点和容忍度、Pod优先级和抢占、ConfigMaps和Secrets、Kubectl Debug、请求和限制、自定义资源定义(CRDs)以及Kubernetes API。这些技巧提高了Kubernetes的管理、可伸缩性和安全性。
预训练大型语言模型在上下文少例学习方面表现出非凡能力。最近的发展是使用对每个输入查询量身定制的示例进行检索,提高了学习效率和可伸缩性。对检索式少例学习领域的研究进行了广泛概述回顾,讨论了不同设计选择。
本文介绍了一种基于仿射最大化拍卖的机器学习方法,用于自动化竞拍设计。该方法通过限制机制在虚拟估值组合拍卖中解决了可伸缩性和收入非可微性问题,并在大规模拍卖中展现出良好的效果和可伸缩性。
本研究提出了一种名为FedSurF++的算法,用于医疗领域的生存分析。该算法在隐私保护方面表现出色,并在两个真实数据集上展示了成功。具有高效性、鲁棒性和隐私性,可提高生存分析的可伸缩性和效果。
该文章介绍了一种基于知识蒸馏的联邦学习方法FedSDD,通过构建教师模型的聚合集合来提高可伸缩性和性能。该方法在基准数据集上表现优于其他联邦学习方法。
SQL Server是Microsoft公司推出的关系型数据库管理系统,具有使用方便、可伸缩性好等优点。安装步骤包括下载程序、安装、选择版本、接受许可条款、功能选择、实例配置、服务账户配置、数据库引擎配置、数据目录设置等。
该研究提出了一种整合区块链技术的创新方法,以增强参与节点的可信度和实现高效的模型更新。该系统旨在创建一个公平、安全和透明的环境,促进合作机器学习,同时保护数据隐私。研究展示了该方法在半集中式联邦学习 - 区块链系统方面的优势。
该文介绍了一种新的数据驱动方法,用于部分多图匹配。该方法基于图上深度学习的最新进展,验证了在多图循环一致性保证的情况下的有效性,并在用合成图匹配数据集进行的受控实验集上证明了该方法的可伸缩性和对高度偏差的鲁棒性。
本研究提出了一种基于关注条件神经过程模型的新型 LAL 方法,用于分类,适应特定设置和非标准目标,实验证明其优于多种基线方法。需要进一步提高可伸缩性。该研究为未来的 LAL 工作提供启发。
本研究提出了一种基于关注条件神经过程模型的新型 LAL 方法,用于分类,适应特定设置,优于多种基线方法。需要进一步提高可伸缩性。该研究为未来的 LAL 工作提供启发。
功能需求定义系统应做什么,非功能性需求规定系统应是什么样。可伸缩性、可用性、可扩展性、一致性、弹性、可观察性、安全性、耐用性、敏捷性是衡量系统质量的关键因素。构建系统需考虑流量模式、延迟、部署标记、灾难恢复、辅助功能、易学性、日志记录、安全性、复制、容错、可归档性、可维护性、可测试性、可部署性、可安装性、可升级性、可移植性、可配置性、兼容性等。
该研究介绍了Deep Operator Network(DeepONet)在核工程领域的应用,展现了出色的预测准确性和高效的计算能力。通过广泛的基准测试和评估,研究证明了DeepONet在解决复杂粒子传输问题方面的可伸缩性。该研究为核工程研究和应用提供了一个有希望和具有变革性的工具,可以推动数字孪生系统的发展和代理建模技术的有效利用。
线程池是.NET中的一种服务,用于管理和分配线程,提高应用程序的性能和可伸缩性。使用时需注意避免阻塞、过多创建线程和使用线程本地存储等问题。示例代码展示了如何使用线程池执行多个工作项。
本文强调了ToB产品中非功能性需求的重要性,包括可伸缩性、安全性、性能和弹性。文章提出了将非功能性需求左移,伴随着软件生命周期一起成长的思想,并强调了监控的重要性。最后,文章认为架构是演进出来的,不是设计出来的,符合持续架构的思想。
完成下面两步后,将自动完成登录并继续当前操作。