

💡
原文中文,约1900字,阅读约需5分钟。
📝
内容提要
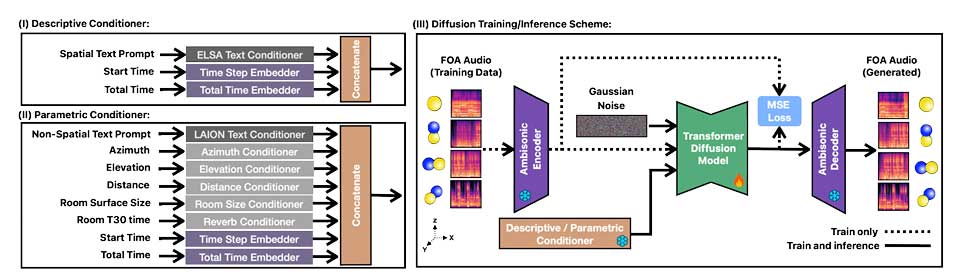
ImmerseDiffusion是一种新型生成音频模型,能够根据空间、时间和环境条件生成高质量的3D沉浸式音景。该模型专注于一阶Ambisonics音频,支持描述性和参数化模式,适用于电影和游戏等场景,表现出色,具有广泛应用前景。
🎯
关键要点
- ImmerseDiffusion是一种新型生成音频模型,能够生成高质量的3D沉浸式音景。
- 该模型专注于一阶Ambisonics音频,适用于电影和游戏等场景。
- 现有生成式音频模型通常只能生成单声道或立体声,无法准确定位声音源。
- ImmerseDiffusion通过空间音频编解码器和潜在扩散模型实现声音的精准空间定位。
- 模型包含描述性条件模块和参数化条件模块,适用于不同应用场景。
- 评估结果显示,ImmerseDiffusion在生成质量和空间一致性方面表现出色。
- 研究团队提出了新的评估指标来衡量生成音频的质量和空间一致性。
- ImmerseDiffusion的核心架构包括空间自编码器、条件块和扩散模型。
- 模型在多个数据集上训练,能够生成高质量的空间音频。
- ImmerseDiffusion在虚拟现实、电影音效制作、教育和医疗等领域具有广泛应用前景。
- 研究人员计划进一步优化模型性能,提高生成音频的空间定位精度和环境适应性。
➡️
