
推进可扩展的文本转语音合成:Llasa 基于 Transformer 的框架可提高语音质量和情感表达能力
内容提要
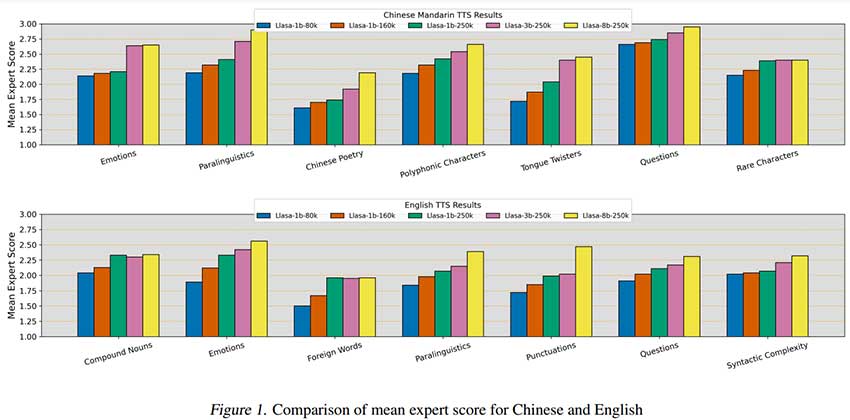
研究表明,扩展推理时间计算可提升语音合成质量。Llasa 模型采用单级 TTS 架构,优化语音标记生成,增强自然度和情感表现。实验结果显示该模型在多个指标上表现优异,鼓励进一步研究。
关键要点
-
扩展推理时间计算可提升语音合成质量。
-
Llasa 模型采用单级 TTS 架构,优化语音标记生成。
-
该模型在多个指标上表现优异,增强自然度和情感表现。
-
现有 TTS 系统通常采用多阶段架构,Llasa 模型通过直接建模离散语音标记解决了低效率问题。
-
Llasa 模型在零样本语音合成、跨语言自适应和情感保存方面具有最先进的性能。
-
集成扩展策略可提高 ASR 准确性,弥合文本和语音 LLM 应用之间的差距。
-
Llasa 模型使用语音标记器 Xcodec2,将波形编码为离散标记,解码为高质量音频。
-
研究表明,推理时间计算扩展提高了语音的自然度、韵律和理解力。
-
Llasa 的实验展示了强大的零样本 TTS 功能,鼓励进一步研究。
延伸解读
推理时间扩展的优势
Llasa 模型通过推理时间扩展,显著提升了语音合成的自然度和情感表达能力。这一策略在传统 TTS 系统中尚未得到充分应用,表明在语音合成领域,优化推理过程同样重要。研究者应关注如何在实际应用中有效利用这一优势,以提升用户体验。
单级架构的创新
Llasa 模型采用单级 TTS 架构,直接建模离散语音标记,解决了多级管道的低效率问题。这种创新不仅降低了系统复杂性,还增强了可扩展性。对于开发者而言,理解这一架构的优势有助于在未来的 TTS 系统设计中做出更有效的选择。
情感表达与音色一致性
Llasa 模型在情感表达和音色一致性方面表现优异,尤其是在零样本语音合成和跨语言自适应中。这一特性使得该模型在多语言环境下的应用潜力巨大,开发者在设计多语言 TTS 系统时应考虑如何利用这一优势来提升系统的适应性和用户满意度。
延伸问答
Llasa 模型的主要特点是什么?
Llasa 模型采用单级 TTS 架构,优化语音标记生成,增强自然度和情感表现,具有最先进的零样本语音合成和跨语言自适应能力。
如何提高语音合成的质量?
扩展推理时间计算可以提升语音合成质量,通过增加计算资源来提高输出质量和任务复杂性处理能力。
Llasa 模型与传统 TTS 系统有什么不同?
Llasa 模型通过直接建模离散语音标记,采用单级架构,解决了传统多级 TTS 系统的低效率问题。
Llasa 模型在情感表达方面的表现如何?
Llasa 模型通过推理时间计算扩展,显著提高了情感表现力和音色一致性。
Llasa 模型的实验结果如何?
实验结果显示,Llasa 模型在多个指标上表现优异,尤其是在零样本语音合成和语音质量感知评估方面。
Llasa 模型的开发背景是什么?
Llasa 模型由多所大学和研究机构的研究人员联合开发,旨在提高文本转语音合成的质量和效率。
