
Datadog如何构建自定义数据库以每秒接收数十亿个指标
内容提要
Datadog的工程团队开发了Monocle,一个高效的时间序列存储引擎,通过分离数据与元数据、使用Kafka进行数据分发,实现了快速响应和高并发处理,显著提升了系统性能。
关键要点
-
Datadog的工程团队开发了Monocle,一个高效的时间序列存储引擎。
-
Monocle通过分离数据与元数据、使用Kafka进行数据分发,实现了快速响应和高并发处理。
-
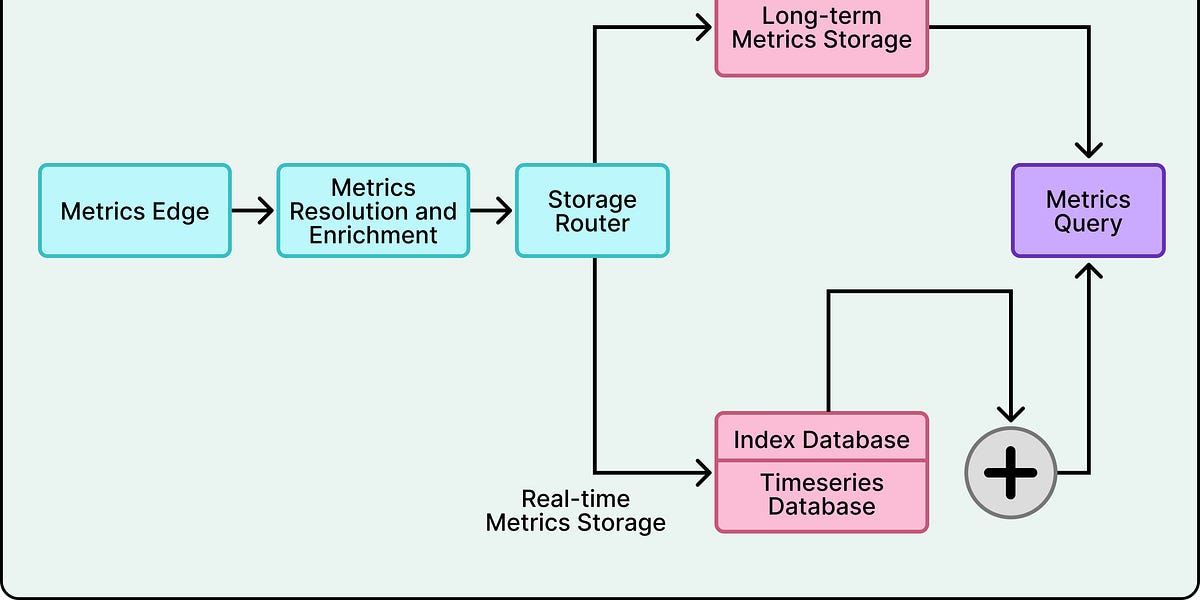
Datadog的Metrics Platform负责收集、处理、存储和服务客户的所有指标。
-
数据存储分为长期指标存储和实时指标存储,后者处理99%的查询。
-
Monocle的设计采用了哈希标签的简单数据模型,提高了查询效率。
-
Monocle使用线程每核心架构,避免了传统数据库中的性能瓶颈。
-
Monocle的存储结构为日志结构合并树(LSM-Tree),适合写入密集型工作负载。
-
通过Admission Control和成本调度系统,Monocle在高负载下保持响应性。
-
Datadog计划将Index Database和RTDB合并为一个统一系统,以提高性能。
-
未来的计划包括动态路由和列式数据库格式的转变。
延伸解读
Monocle的设计优势
Monocle通过分离数据与元数据,采用哈希标签的简单数据模型,显著提高了查询效率。这种设计使得在处理高并发请求时,系统能够快速响应,避免了传统数据库中的性能瓶颈。
Kafka的关键角色
在Monocle的架构中,Kafka不仅用于数据分发,还充当写前日志,确保数据安全性和高可用性。这种设计减少了节点间的协调需求,提高了系统的稳定性和速度。
未来的发展方向
Datadog计划将Index Database和RTDB合并为一个统一系统,并转向列式数据库格式。这一转变将进一步提升查询性能,尤其是在分析复杂数据时,值得关注其实施过程中的挑战与创新。
延伸问答
Datadog的Monocle是什么?
Monocle是Datadog开发的高效时间序列存储引擎,旨在处理实时指标。
Monocle如何提高查询效率?
Monocle通过分离数据与元数据、使用哈希标签模型和线程每核心架构来提高查询效率。
Datadog的实时指标存储系统是如何工作的?
实时指标存储系统处理最新24小时的数据,支持99%的查询,主要用于实时监控和仪表盘更新。
Monocle的存储结构是什么?
Monocle采用日志结构合并树(LSM-Tree)作为存储结构,适合写入密集型工作负载。
Datadog如何确保数据的安全性和稳定性?
Datadog使用Kafka作为写前日志,确保数据安全,并通过复制机制实现高可用性。
Datadog未来对Monocle的计划是什么?
Datadog计划将索引数据库和实时数据库合并为一个统一系统,并转向列式数据库格式以提高性能。
