
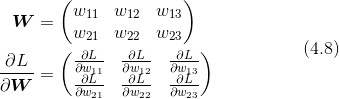
microgpt 解析
内容提要
本文介绍了microgpt的核心概念和实现,包括GPT的训练和推理过程。通过简化的代码示例,阐述了数据集、分词器和矩阵在模型训练中的应用,重点讲解了推理过程中的token预测、梯度下降法及模型参数更新。此外,文章探讨了多头自注意力机制和Transformer架构的基本原理,以帮助初学者理解GPT的工作原理。
关键要点
-
microgpt模拟了GPT的训练和推理流程,适合初学者理解核心思想。
-
推理过程从BOS开始预测token,直到再次遇到BOS结束。
-
数据集使用names.txt,Tokenizer将字符串转换为数字序列。
-
梯度用于指导参数调整,梯度下降法用于优化模型参数。
-
GPT的整体架构包括Embedding、Transformer层和LM Head。
-
多头自注意力机制通过Q、K、V矩阵实现信息的提取和组合。
-
训练过程通过反向传播计算梯度并更新模型参数,最终生成文本。
延伸解读
理解推理过程的重要性
文章详细描述了microgpt的推理过程,从BOS开始预测token,直到再次遇到BOS结束。这一过程不仅是生成文本的关键,也是理解模型如何处理输入的基础。初学者应特别关注这一流程,以便更好地掌握模型的工作原理。
数据集与分词器的作用
microgpt使用的names.txt数据集和Tokenizer的设计至关重要。Tokenizer将字符串转换为数字序列,使得模型能够处理文本数据。理解这一转换过程有助于读者认识到数据预处理在模型训练中的重要性,尤其是在处理更复杂的数据集时。
梯度下降法的核心概念
文章中提到的梯度下降法是优化模型参数的关键。通过不断调整参数以最小化损失函数,模型能够逐步提高预测的准确性。读者应关注学习率的设置和梯度的计算方式,这些因素直接影响模型的训练效果和收敛速度。
延伸问答
microgpt的核心概念是什么?
microgpt模拟了GPT的训练和推理流程,适合初学者理解核心思想。
推理过程是如何进行的?
推理过程从BOS开始预测token,直到再次遇到BOS结束。
数据集和分词器在模型训练中有什么作用?
数据集使用names.txt,Tokenizer将字符串转换为数字序列,以便模型处理。
梯度下降法在模型训练中是如何应用的?
梯度下降法用于优化模型参数,通过调整参数值来减少损失。
多头自注意力机制是如何工作的?
多头自注意力机制通过Q、K、V矩阵实现信息的提取和组合。
microgpt的整体架构包括哪些部分?
microgpt的整体架构包括Embedding、Transformer层和LM Head。
