
基于LanceDB和Amazon S3的可扩展弹性数据库及搜索解决方案,支持超过10亿个向量
内容提要
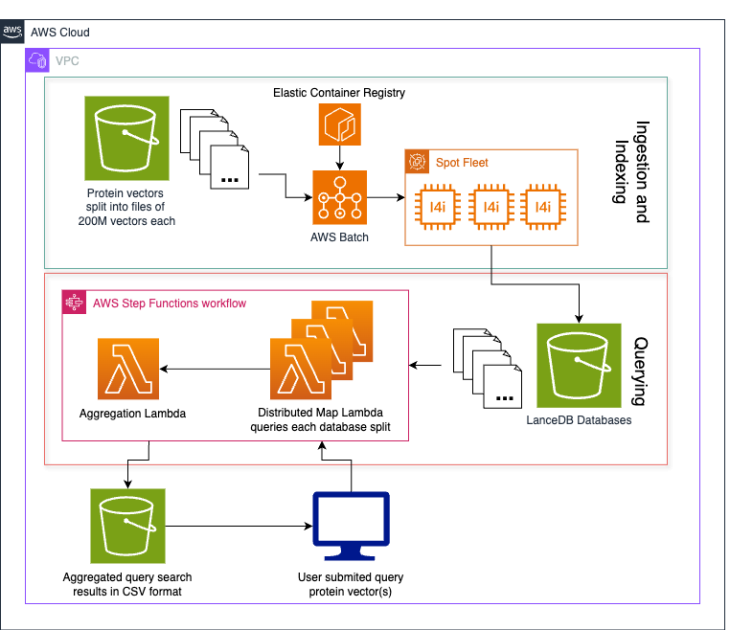
Metagenomi利用AWS和LanceDB开发了一种高效的蛋白质数据库,能够处理数十亿种酶的发现。通过蛋白质向量化和分桶存储,快速查询最近邻,促进基因编辑系统的构建,推动治疗药物的开发。
关键要点
-
Metagenomi利用AWS和LanceDB开发高效蛋白质数据库,处理数十亿种酶的发现。
-
通过蛋白质向量化和分桶存储,快速查询最近邻,促进基因编辑系统的构建。
-
LanceDB是一个开源向量数据库,适合快速近似最近邻搜索,支持无服务器架构。
-
数据向量化使用蛋白质语言模型,将每个蛋白质转换为生物学上有意义的向量。
-
数据分桶将蛋白质向量分成均匀大小的部分,以加速索引和查询过程。
-
使用AWS Lambda和LanceDB API进行数据库查询,支持用户提供的查询向量。
-
优化查询大批量向量的方案是将数据库桶下载到本地进行查询。
-
Metagenomi的数据库包含35亿个向量嵌入,存储成本低,查询成本极低。
-
建议使用存储优化实例进行数据摄取和索引,以提高性能和节省成本。
-
该解决方案可扩展到其他向量化数据集,支持未来需求的数据库解决方案。
延伸解读
可扩展性与灵活性
Metagenomi的解决方案利用LanceDB和AWS S3的组合,展示了在处理大规模数据时的可扩展性。通过将数据分桶存储,系统能够灵活应对不断增长的蛋白质数据库需求。这种架构不仅适用于蛋白质数据,也可以扩展到其他向量化数据集,适应未来的研究需求。
成本效益分析
使用AWS Lambda和S3进行查询,Metagenomi实现了低成本的数据库解决方案。根据文章,查询成本极低,且存储费用相对可控。这种无服务器架构使得在不需要持续运行服务器的情况下,仍能高效处理数十亿个向量的查询,适合预算有限的研究机构。
数据处理的挑战与解决方案
在处理数十亿个蛋白质向量时,数据的向量化和索引是关键步骤。Metagenomi通过将数据分成均匀大小的桶,优化了索引过程。这种方法不仅加快了数据处理速度,还允许逐步增加数据,避免了重新索引的复杂性,适合动态变化的数据环境。
延伸问答
Metagenomi的蛋白质数据库有什么特点?
Metagenomi的蛋白质数据库能够处理数十亿种酶的发现,使用LanceDB和AWS构建,支持快速查询和低存储成本。
LanceDB如何支持快速查询?
LanceDB是一个开源向量数据库,支持快速近似最近邻搜索,适合无服务器架构,能够直接从Amazon S3查询数据。
如何将蛋白质向量化?
蛋白质向量化通过使用蛋白质语言模型,将每个蛋白质转换为生物学上有意义的向量,通常生成960维的向量表示。
Metagenomi的数据库如何处理大规模查询?
Metagenomi的数据库通过将数据分桶并使用AWS Lambda进行查询,能够高效处理大规模的查询请求。
使用AWS Lambda进行数据库查询的优势是什么?
使用AWS Lambda进行查询可以实现按需访问,无需持续运行的服务器,降低了查询成本。
Metagenomi的解决方案如何促进基因编辑系统的构建?
通过快速查询最近邻,Metagenomi的解决方案加速了新酶的发现,从而促进了基因编辑系统的构建。
