

大模型硬件的终局推演:GPU与LPU的异构联姻
💡
原文中文,约1300字,阅读约需3分钟。
📝
内容提要
AI 在处理超长上下文时面临算力挑战,需要软硬件协同解决。采用分离式架构,将重型算力与低延迟缓存结合,优化编译器以确保数据流稳定。基于 TGV 的 CoPoS 封装提升了数据传输带宽,推动算力的突破。
🎯
关键要点
-
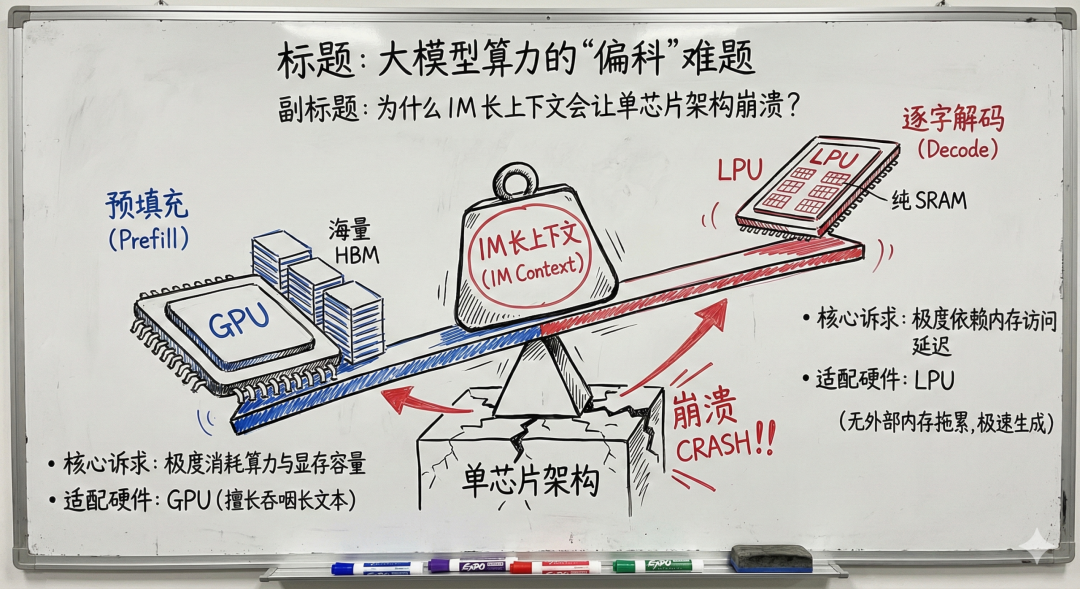
AI 在处理超长上下文时面临算力挑战,尤其在预填充和解码阶段。
-
采用分离式架构,通过重型算力和极速缓存的结合来优化性能。
-
GPU 负责处理长文本并生成 KV Cache,LPU 则负责低延迟的逐字解码。
-
编译器的拓扑扩展技术确保数据流的稳定性,解决了 GPU 和 LPU 之间的动态性问题。
-
基于 TGV 的 CoPoS 封装突破了传统硅基封装的限制,提升了数据传输带宽。
-
CoPoS 封装允许将多种计算单元高密度集成,减少了系统体积。
-
玻璃基板的特性消除了网络协议延迟,提升了 GPU 与 LPU 之间的数据转移效率。
-
未来的算力奇点将依赖于软硬件的协同进化,而不仅仅是先进制程的堆砌。
➡️
