
大模型硬件的终局推演:GPU与LPU的异构联姻
内容提要
AI 在处理超长上下文时面临算力挑战,需要软硬件协同解决。采用分离式架构,将重型算力与低延迟缓存结合,优化编译器以确保数据流稳定。基于 TGV 的 CoPoS 封装提升了数据传输带宽,推动算力的突破。
关键要点
-
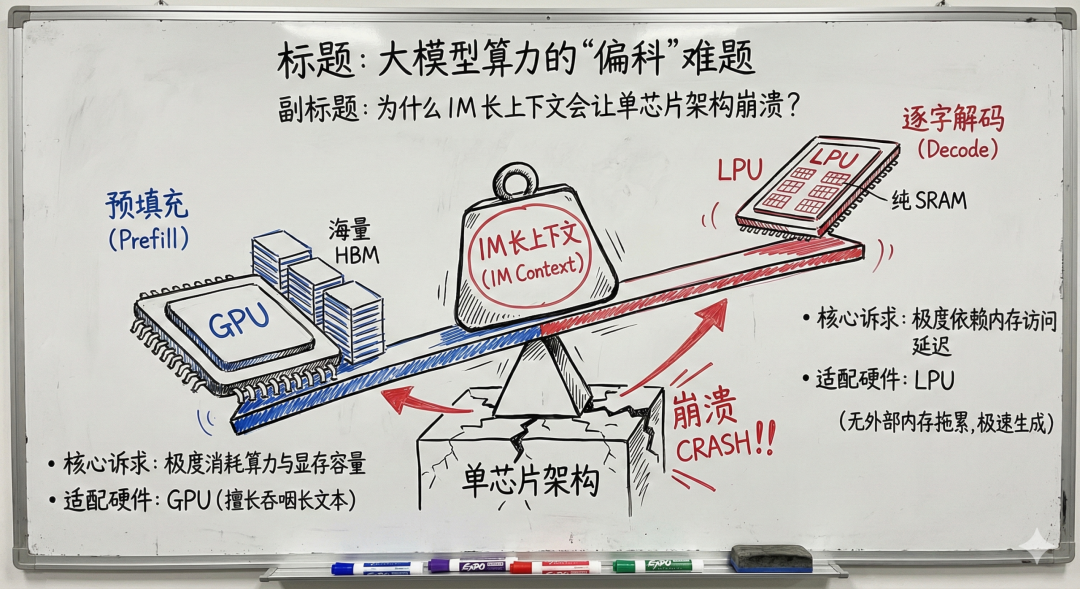
AI 在处理超长上下文时面临算力挑战,尤其在预填充和解码阶段。
-
采用分离式架构,通过重型算力和极速缓存的结合来优化性能。
-
GPU 负责处理长文本并生成 KV Cache,LPU 则负责低延迟的逐字解码。
-
编译器的拓扑扩展技术确保数据流的稳定性,解决了 GPU 和 LPU 之间的动态性问题。
-
基于 TGV 的 CoPoS 封装突破了传统硅基封装的限制,提升了数据传输带宽。
-
CoPoS 封装允许将多种计算单元高密度集成,减少了系统体积。
-
玻璃基板的特性消除了网络协议延迟,提升了 GPU 与 LPU 之间的数据转移效率。
-
未来的算力奇点将依赖于软硬件的协同进化,而不仅仅是先进制程的堆砌。
延伸解读
软硬件协同的重要性
在AI处理超长上下文时,算力的需求呈现出两极化特征。GPU与LPU的分离式架构通过各自的优势互补,能够有效应对预填充和解码阶段的挑战。这种软硬件协同的模式不仅提升了性能,也为未来的AI应用提供了更大的灵活性和可扩展性。
CoPoS封装的创新意义
基于TGV的CoPoS封装技术突破了传统硅基封装的限制,允许更高密度的计算单元集成。这种创新不仅减少了系统体积,还显著提升了数据传输带宽,解决了GPU与LPU之间的延迟问题,为高性能计算提供了新的可能性。
编译器的关键角色
编译器在GPU与LPU的协同工作中扮演着至关重要的角色。通过拓扑扩展技术,编译器能够确保数据流的稳定性,避免因动态性带来的不确定性。这一技术的成功实施是实现高效算力的基础,值得关注其未来的发展方向。
延伸问答
AI在处理超长上下文时面临哪些算力挑战?
AI在预填充阶段需要大量浮点算力和显存,而在解码阶段则依赖极低的内存延迟。
什么是分离式架构,它如何优化AI性能?
分离式架构通过将重型算力和极速缓存结合,使GPU处理长文本生成KV Cache,而LPU负责低延迟逐字解码。
CoPoS封装如何提升数据传输带宽?
CoPoS封装使用大尺寸玻璃面板,消除了网络协议延迟,使GPU与LPU之间的数据转移带宽达到数十TB/s。
编译器在GPU与LPU协同工作中起什么作用?
编译器通过拓扑扩展技术确保数据流的稳定性,解决了GPU和LPU之间的动态性问题。
未来的算力奇点将如何依赖软硬件的协同进化?
未来的算力奇点将依赖于跨越异构架构的软件编译器和先进封装的物理设计,而不仅仅是先进制程的堆砌。
玻璃基板的特性对AI硬件有什么影响?
玻璃基板的电介质特性消除了网络协议延迟,并且与硅的热膨胀系数匹配,提升了数据转移效率。
