
视觉RAG:实现对任意文档的搜索
内容提要
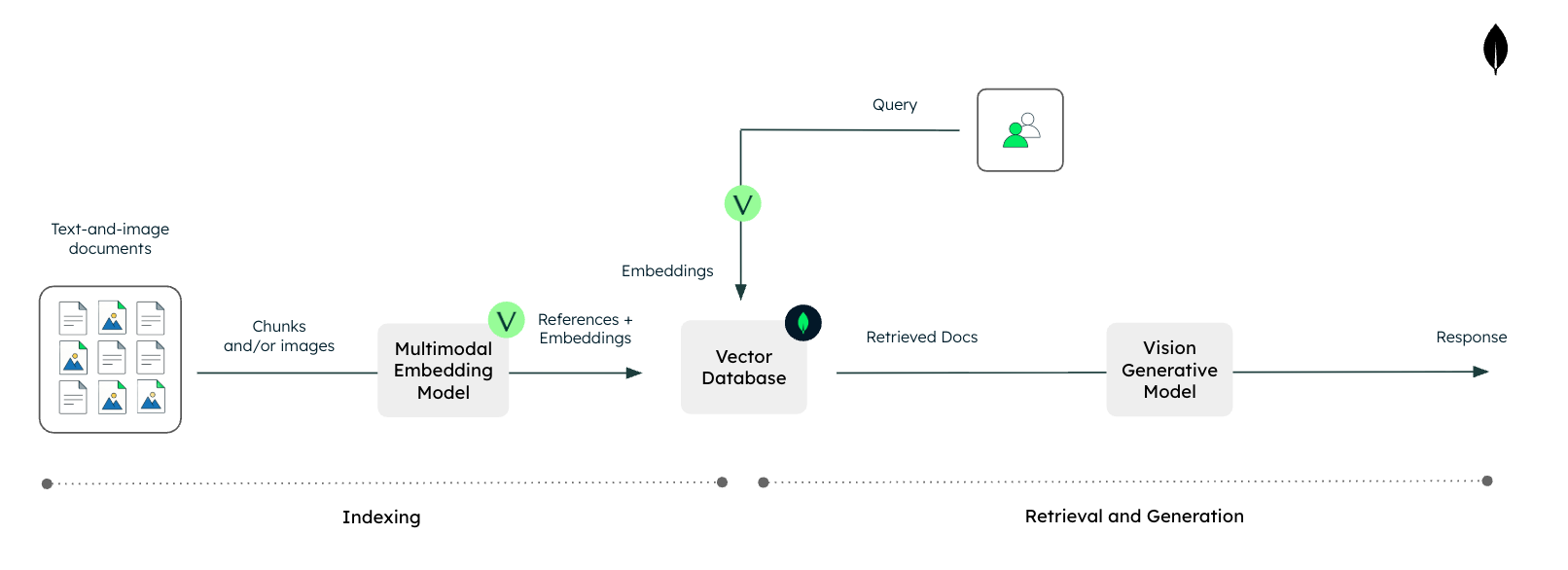
Vision RAG是一种新型的信息检索和生成技术,能够高效处理复杂文档中的文本和图像。它通过多模态嵌入模型直接索引整个文档,避免了传统OCR的低效和高成本,提升了企业数据的搜索和分析能力,并能从图表和图像中提取关键信息。
关键要点
-
Vision RAG是一种新型的信息检索和生成技术,能够高效处理复杂文档中的文本和图像。
-
Vision RAG通过多模态嵌入模型直接索引整个文档,避免了传统OCR的低效和高成本。
-
该技术提升了企业数据的搜索和分析能力,能够从图表和图像中提取关键信息。
-
传统的文本RAG主要处理纯文本数据,而Vision RAG能够处理包含文本和图像的复杂文档。
-
多模态嵌入模型能够生成捕捉内容意义和结构的向量表示,简化了信息提取过程。
-
Vision RAG使用单一编码器处理文本和视觉输入,确保文本和视觉特征在同一向量空间中一致性。
-
通过Vision RAG,企业能够更有效地访问丰富的多模态数据,降低工程复杂性和成本。
延伸解读
多模态嵌入模型的优势
Vision RAG通过多模态嵌入模型,能够同时处理文本和图像数据。这种方法不仅提高了信息检索的效率,还减少了传统OCR技术的局限性,如高成本和低准确率。企业在处理复杂文档时,可以更轻松地提取关键信息,提升数据分析能力。
应用场景与潜在风险
Vision RAG适用于各种企业数据,如财务报告、技术文档等。然而,尽管其优势明显,企业在实施时仍需关注数据隐私和安全性,确保敏感信息不会在处理过程中泄露。此外,技术的复杂性可能需要专业人员进行维护和优化。
与传统RAG的比较
传统的文本RAG主要处理纯文本数据,而Vision RAG则能够处理包含图像和文本的复杂文档。这一转变使得信息检索更加全面,尤其是在需要从图表和图像中提取信息时,Vision RAG展现出更强的能力,适应了现代企业对多样化数据的需求。
延伸问答
Vision RAG是什么技术,它的主要功能是什么?
Vision RAG是一种新型的信息检索和生成技术,能够高效处理复杂文档中的文本和图像,提升企业数据的搜索和分析能力。
Vision RAG如何解决传统OCR的不足?
Vision RAG通过多模态嵌入模型直接索引整个文档,避免了传统OCR的低效和高成本。
多模态嵌入模型在Vision RAG中起什么作用?
多模态嵌入模型生成捕捉内容意义和结构的向量表示,简化了信息提取过程。
Vision RAG如何处理包含文本和图像的复杂文档?
Vision RAG使用单一编码器处理文本和视觉输入,确保文本和视觉特征在同一向量空间中一致性,从而实现对复杂文档的有效检索。
企业使用Vision RAG有什么好处?
企业能够更有效地访问丰富的多模态数据,降低工程复杂性和成本,提升数据的搜索和分析能力。
Vision RAG的实现步骤有哪些?
实现步骤包括安装必要的库、初始化API客户端、提取视觉内容、构建多模态索引、定义RAG组件和运行查询等。
