


使用Amazon Nova模型实现自动化视频高光剪辑
亚马逊AWS官方博客
·

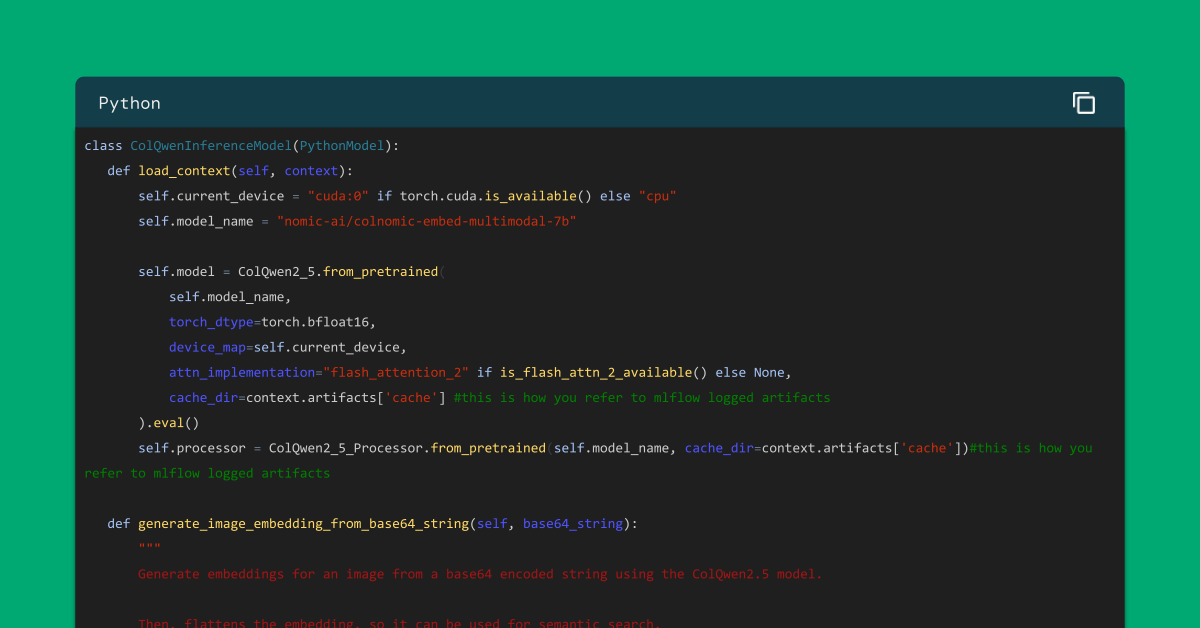
Llama.cpp 和 GGUF 中的多模态嵌入
Jina AI
·
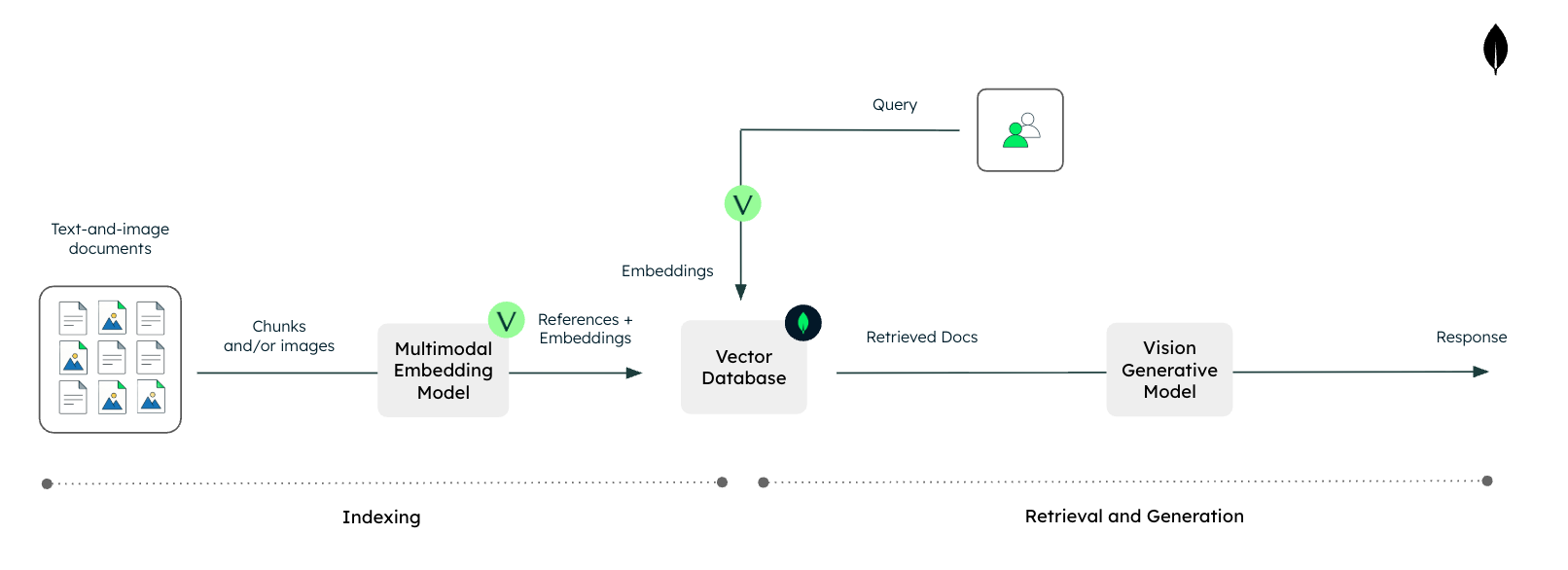
通过多模态RAG整合患者数据
Databricks
·
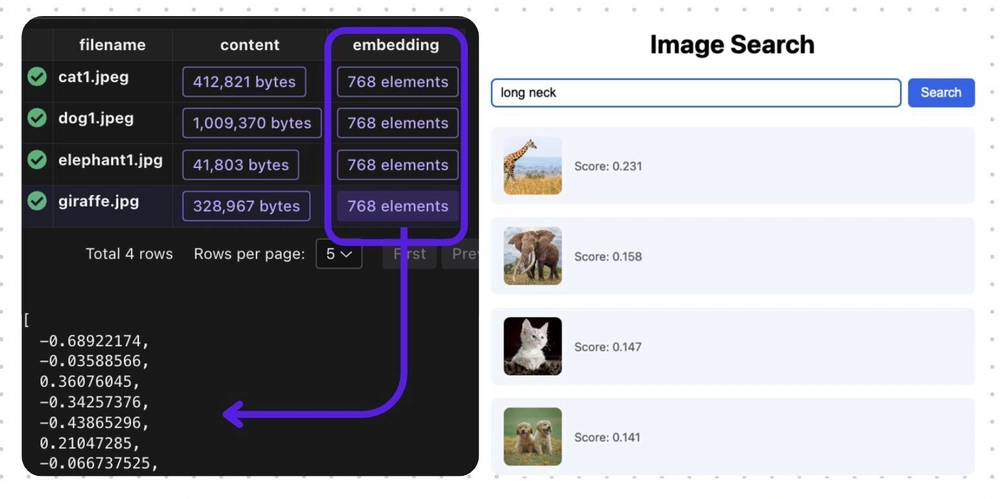
如何构建具有语义理解的图像搜索
DEV Community
·

构建一个用于视频内容搜索和分析的RAG系统
DEV Community
·

构建视频内容搜索与分析的RAG系统
DEV Community
·

人工智能如何变革信息检索及其对您的影响
DEV Community
·
