
TokenBridge:弥合可视化生成中连续和离散token表示法之间的差距
内容提要
自回归视觉生成模型通过离散和连续token实现高质量图像合成。TokenBridge采用新颖的训练后量化技术,显著提升生成效果,且在参数更少的情况下优于传统模型,为未来视觉合成技术提供新思路。
关键要点
-
自回归视觉生成模型是一种突破性的图像合成方法,灵感来自语言模型的token预测机制。
-
该模型利用图像标记器将视觉内容转换为离散或连续token,促进多模态集成。
-
确定最佳标记表示策略是该领域面临的关键挑战,离散和连续token表示的选择影响模型复杂性和生成质量。
-
现有方法包括视觉标记化,探索连续和离散token表示的优缺点。
-
TokenBridge是由香港大学、字节跳动、巴黎综合理工学院和北京大学的研究人员提出的,旨在弥合连续和离散token表示之间的差距。
-
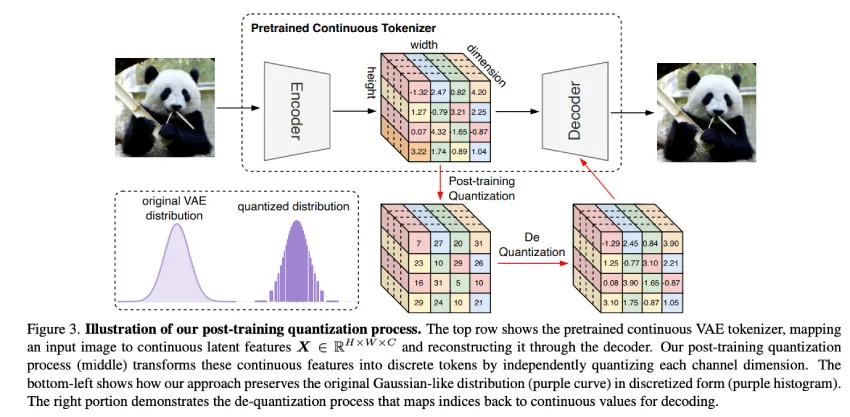
TokenBridge通过新颖的训练后量化技术和维度量化策略,提升了生成效果并减少了参数数量。
-
TokenBridge-L模型以4.86亿个参数获得了1.76的FID,优于传统的离散token模型。
-
H模型配置进一步验证了TokenBridge的有效性,FID为1.55,且参数数量略少于其他模型。
-
研究表明,TokenBridge能够有效桥接离散和连续token表示,为未来的视觉合成技术提供新思路。
延伸解读
TokenBridge的创新意义
TokenBridge通过引入训练后量化技术,成功弥合了连续和离散token表示之间的差距。这一创新不仅提升了生成效果,还减少了模型参数,使得视觉生成技术在效率和质量上都有了显著进步。
模型选择的影响
在视觉生成中,选择合适的token表示方式至关重要。离散和连续token各有优缺点,影响模型的复杂性和生成质量。TokenBridge的研究表明,合理的表示策略可以有效提升生成效果,值得研究者关注。
未来研究的方向
TokenBridge的成功为未来的视觉合成技术提供了新的思路。研究者可以在此基础上探索更多的量化技术和模型架构,以进一步提高生成质量和效率,推动该领域的发展。
延伸问答
TokenBridge的主要创新是什么?
TokenBridge通过新颖的训练后量化技术和维度量化策略,提升了生成效果并减少了参数数量。
自回归视觉生成模型的灵感来源于什么?
自回归视觉生成模型的灵感来自语言模型的token预测机制。
TokenBridge如何解决离散和连续token表示的挑战?
TokenBridge利用连续token的强大表示能力,同时保持离散token的建模简单性,从而弥合两者之间的差距。
TokenBridge的性能如何与传统模型比较?
TokenBridge-L模型以4.86亿个参数获得了1.76的FID,优于传统的离散token模型。
TokenBridge的研究团队来自哪些机构?
TokenBridge的研究团队包括香港大学、字节跳动、巴黎综合理工学院和北京大学的研究人员。
TokenBridge的维度量化策略有什么特点?
TokenBridge实施了一种独特的维度量化策略,可以独立离散化每个特征维度,并辅以轻量级自回归预测机制。
