腾讯开源的混元图像模型2.1支持2K高清生图,具备强大的生成效果和复杂语义理解能力,迅速成为Hugging Face全球第三热门,适用于多种视觉创作需求,助力设计师高效创作。
DiT模型受到质疑,网友认为其数学和形式上存在错误,甚至怀疑是否使用了Transformer。作者谢赛宁回应称,科学进步需要发现模型的不足,强调实证方法的重要性,并反驳质疑,指出Tread模型与DiT无关,且DiT在生成效果上仍具优势。
全景视频是虚拟现实的重要组成部分,提升用户体验。尽管制作需要专业设备,但生成式视频模型的进展降低了创作门槛。北京大学推出的PanoWan框架,通过纬度感知采样等技术,解决了全景视频生成中的畸变问题,并构建了包含1.3万视频的PanoVid数据集,提升了生成效果和编辑能力。
何恺明的新论文提出了一种名为Dispersive Loss的正则化方法,旨在提升扩散模型的生成效果。该方法无需预训练和数据增强,通过正则化中间表示来增强特征分散性,简化实现并提高生成质量。实验结果显示,Dispersive Loss在多种模型上显著改善生成效果,具有广泛的应用潜力。
腾讯推出混元图像2.0,实现边说边画的实时图像生成,响应速度达到毫秒级。用户可通过文字或手绘输入,系统即时生成图像。该模型具备更大参数和高效图像编解码器,提升了生成效果和真实感。
本文提出了AlignRAG框架,旨在解决检索增强生成(RAG)模型中推理轨迹与检索证据不对齐的问题。AlignRAG通过迭代的批评驱动对齐步骤,性能优于现有方法,并能无缝集成到RAG管道中,提升检索意识生成的效果。
本文探讨了将AI设计产品融入艺术设计工作流的可能性,比较了Stable Diffusion、Midjourney和腾讯的混元3D等多种图像生成模型。不同模型在生成速度、质量和理解能力上存在显著差异,腾讯的混元3D表现较好,生成效果和速度均令人满意。整体来看,图像生成技术已相对成熟,但仍需优化。
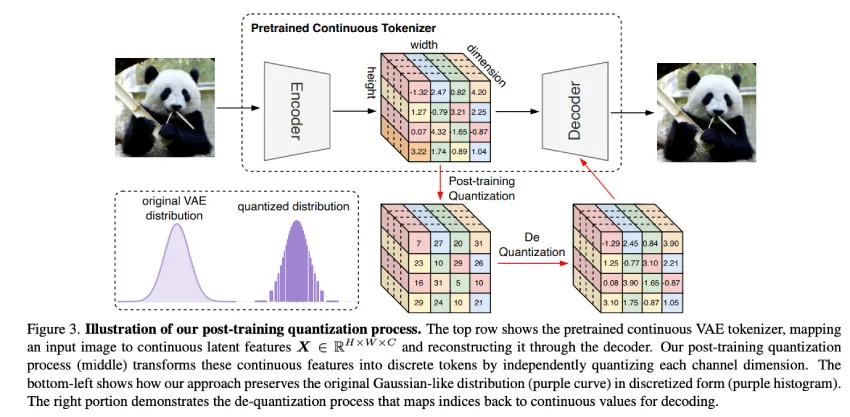
自回归视觉生成模型通过离散和连续token实现高质量图像合成。TokenBridge采用新颖的训练后量化技术,显著提升生成效果,且在参数更少的情况下优于传统模型,为未来视觉合成技术提供新思路。
本文提出了一种基于多模态大型语言模型的广告图像生成方法,旨在提升点击率(CTR)。通过预训练和强化学习,生成与商品特征相符且吸引用户的广告图像。实验结果表明,该方法在CTR预测和生成效果上优于现有技术。
扩散模型与流匹配本质上等价,尽管实现方式不同。扩散模型通过去噪声逐步恢复数据,而流匹配通过可逆变换映射分布。研究表明,两者可灵活结合,利用不同采样策略提升生成效果。
本研究提出了一种新方法,通过结合音频特征与视觉信息,生成自然声音对应的视觉场景图像。该方法在VEGAS和VGGSound数据集上显著提高了生成效果,展示了对生成过程的控制能力,证明了其适用性和通用性。
本研究探讨了大语言模型在检索增强生成中的文档检索顺序的影响,提出使用似然性作为评估工具,证明其与回答准确性相关,并提出优化提示选择与构建的方法,以提升生成效果。
本研究提出了AutoRAG框架,能够自动识别最佳的检索增强生成(RAG)模块组合,从而显著提升特定数据集的生成效果,实验数据可在GitHub上获取。
本研究提出ClusterGAN,通过混合一热编码和连续变量的潜变量进行聚类,结合特定损失函数和逆网络训练,展示了GAN在潜空间中有效保留类别间插值的能力。同时,研究探讨了GAN潜在空间的可解释性和控制方法,提出了无监督技术和基于几何的优化策略,以提升生成效果。
本文提出了多种创新的扩散模型训练框架和策略,如Patch Diffusion、DDM和SFERD,旨在提升生成效果和训练效率。通过引入条件分数函数、时间步骤调度和动量衰减等方法,显著降低计算成本并提高图像质量,为扩散模型的实际应用提供了新的视角和解决方案。
本研究探讨了手势表示维度对3D口语手势生成的影响。结果表明,直接生成3D手势的效果优于先生成2D再转换为3D,强调了手势表示维度的重要性。
本文提出了多种新方法以提升无监督图像分割和生成效果,包括基于槽的注意力机制、自我训练方法和跨图像对象级引导。这些方法在多个数据集上表现优异,尤其在处理复杂图像时,显著提高了分割精度和生成质量。
本研究分析了检索增强生成(RAG)对大型语言模型(LLMs)的影响,提出了新的框架和评估方法,强调外部知识库整合对提高检索精度和答案准确性的重要性。研究发现特定文档类型能显著提升生成效果,并指出未来研究方向。
本文提出了一种名为DDM的扩散模型,通过分解扩散过程来提高生成效果和速度,同时提出了一个新的DPM训练目标。实验结果表明DDM在更少的函数评估方面优于以前的DPM。
本文介绍了一种名为DDM的扩散模型,通过简化扩散过程来提高生成效果和速度。它使用显式转移概率近似图像分布,并通过标准维纳过程控制噪声路径。文章还提出了一个新的DPM训练目标,能够预测噪声和图像成分。实验结果表明,DDM在函数评估方面优于以前的DPM。
完成下面两步后,将自动完成登录并继续当前操作。