
Voice Agents 101: The Architecture Behind AI That Can Converse with Humans
内容提要
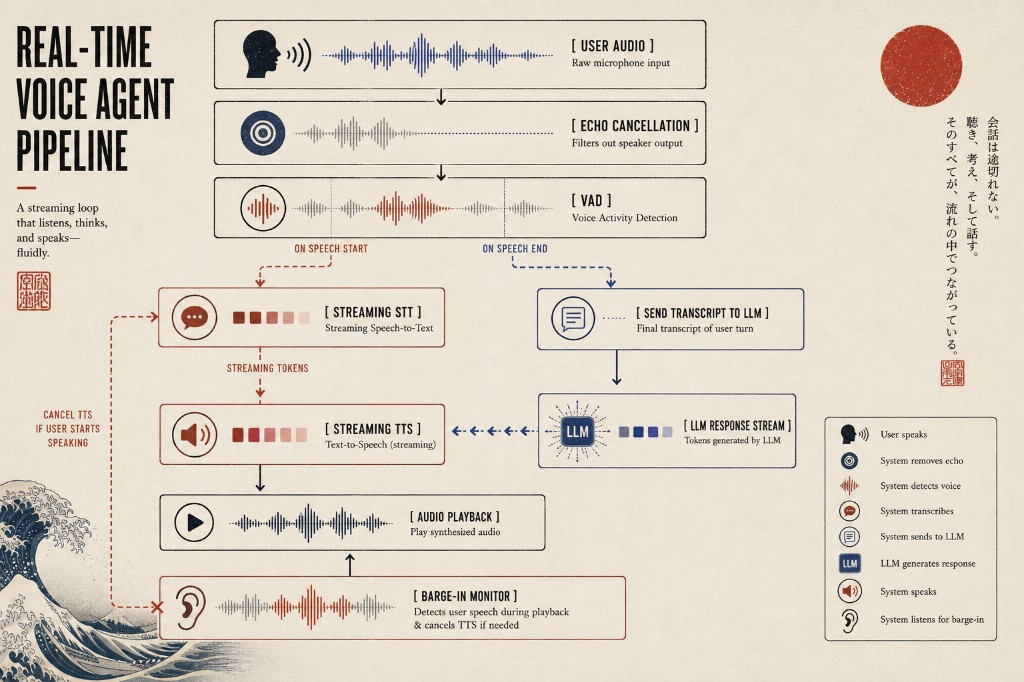
本文探讨了语音智能体的架构,包括语音转文本(STT)、大语言模型(LLM)和文本转语音(TTS)三个阶段。引入音频后,延迟和上下文处理变得复杂。级联模型适合大多数生产环境,而端到端模型在自然对话中更具竞争力。流式传输技术可减少延迟,提升对话自然性。设计中需考虑语音活动检测和话轮管理等技术挑战,以改善用户体验。
关键要点
-
语音智能体的架构包括语音转文本(STT)、大语言模型(LLM)和文本转语音(TTS)三个阶段。
-
引入音频后,延迟和上下文处理变得复杂,语音智能体的每个阶段都面临时间限制。
-
级联模型适合大多数生产环境,提供对每个阶段的完全控制,但会增加延迟和上下文丢失。
-
端到端模型绕过转录步骤,显著降低延迟,但牺牲了对各个组件的可控性。
-
流式传输技术可以减少延迟,使用户在LLM生成回复时就能听到第一个词。
-
全双工模式允许用户和智能体同时说话,提升自然对话体验,但实现难度较大。
-
语音活动检测(VAD)和话轮管理是设计语音智能体时需要解决的技术挑战。
-
在嘈杂环境和多说话人场景中,语音智能体的准确性会显著下降,需要更复杂的处理方法。
-
未来的挑战在于如何在延迟预算内实现更自然的对话体验和更好的记忆管理。
延伸解读
语音智能体的延迟挑战
语音智能体的设计必须考虑延迟问题,理想的响应时间应控制在500-800毫秒以内。超过这个时间,用户会感到不自然,影响对话体验。为了实现流畅的对话,开发者需要优化每个阶段的处理时间,并考虑流式传输技术以减少延迟。
级联模型与端到端模型的权衡
级联模型提供了对每个处理阶段的完全控制,但会增加延迟和上下文丢失。而端到端模型则显著降低了延迟,但牺牲了对各个组件的可控性。选择哪种架构应根据具体应用场景的需求来决定,尤其是在自然对话与工具使用之间的平衡。
嘈杂环境对语音识别的影响
在嘈杂环境中,语音智能体的准确性会显著下降,导致错误的转录和不相关的回复。尽管有工具可以处理某些类型的噪声,但对于复杂的背景音,仍需开发更有效的解决方案,以提升语音识别的可靠性。
延伸问答
语音智能体的架构包括哪些主要阶段?
语音智能体的架构包括语音转文本(STT)、大语言模型(LLM)和文本转语音(TTS)三个阶段。
级联模型和端到端模型有什么区别?
级联模型逐步处理音频,提供对每个阶段的控制,但增加延迟;端到端模型直接处理音频,显著降低延迟,但牺牲了对各个组件的可控性。
如何减少语音智能体的响应延迟?
通过流式传输技术,可以在生成回复时立即开始播放音频,从而减少响应延迟。
全双工模式在语音智能体中有什么重要性?
全双工模式允许用户和智能体同时说话,提升自然对话体验,但实现难度较大。
语音智能体在嘈杂环境中表现如何?
在嘈杂环境中,语音智能体的准确性会显著下降,需要更复杂的处理方法来应对。
语音活动检测(VAD)在语音智能体中有什么作用?
语音活动检测(VAD)用于识别用户何时开始说话,以便智能体能够及时响应并处理输入。
