
TOMM | 针对人脸视频的混合编码方案
内容提要
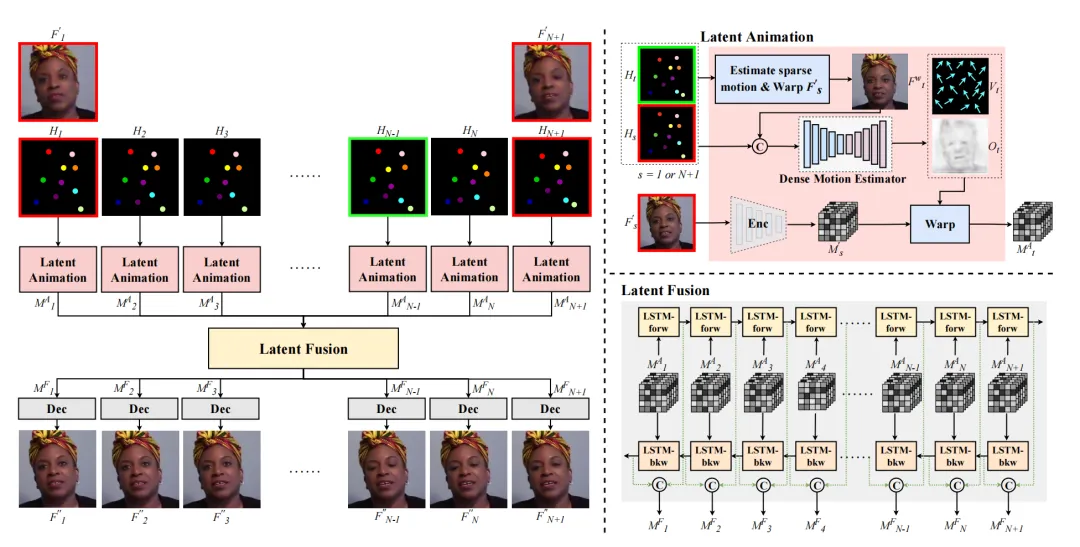
本文提出了一种混合压缩方案,结合传统编码与生成式压缩技术,实现低码率下高保真人脸视频的实时压缩。该方法利用动态参考帧和深度视频生成模型,克服了静态参考帧的局限性,显著提升了视频重建质量和编码效率,适用于社交媒体和实时通信场景。
关键要点
-
提出了一种混合压缩方案,结合传统编码与生成式压缩技术。
-
该方案实现低码率下高保真人脸视频的实时压缩。
-
利用动态参考帧和深度视频生成模型,克服静态参考帧的局限性。
-
显著提升了视频重建质量和编码效率,适用于社交媒体和实时通信场景。
-
传统视频编码技术对所有视频内容采用相同的压缩方式,难以兼顾码率与计算复杂度。
-
现有生成式压缩方法多采用静态参考帧,导致保真度下降。
-
通过动态参考帧提供实时背景与运动信息,结合深度视频生成模型合成非关键帧。
-
该方案在低码率条件下实现高保真人脸视频压缩,具有较高的灵活性。
-
实验表明,该方法在率失真性能与编码复杂度方面优于传统编解码器及现有生成式压缩方法。
-
设计了人像修复模块以提升低质量关键帧的重建质量。
-
提出的混合方案在低码率下实现了更优的视觉质量与重建保真度。
-
该方案支持在消费级设备上实时编解码,显著改善用户体验。
-
未来可将该框架拓展至各类2D/3D视频的低码率高保真压缩。
延伸解读
技术背景与挑战
随着社交媒体和短视频的普及,人脸视频数据量急剧增加,传统视频编码技术难以满足高效压缩的需求。现有生成式压缩方法多依赖静态参考帧,导致在动态场景中保真度下降。本文提出的混合编码方案通过动态参考帧和深度生成模型,克服了这些局限性,提升了视频重建质量。
应用场景与用户体验
该混合压缩方案适用于社交媒体和实时通信场景,能够在消费级设备上实现实时编解码,显著改善用户体验。通过降低存储成本和网络负载,提升传输速度,使得在弱网环境下的视频体验成为可能,拓展了视频通话和会议等应用潜力。
编码复杂度与灵活性
本文提出的方案在编码复杂度上表现优异,能够在保证较低复杂度的同时实现高保真重建。其灵活的码率控制特性使得用户可以根据实际需求调整编码配置,适应不同场景的存储和传输需求,具有较高的实用价值。
延伸问答
什么是混合压缩方案?
混合压缩方案结合了传统编码与生成式压缩技术,旨在低码率下实现高保真人脸视频的实时压缩。
该方案如何提升视频重建质量?
该方案通过动态参考帧提供实时背景与运动信息,并结合深度视频生成模型合成非关键帧,从而提升视频重建质量。
混合压缩方案适用于哪些场景?
该方案适用于社交媒体和实时通信场景,能够显著改善用户体验。
与传统编码技术相比,该方案有什么优势?
该方案在率失真性能、编码复杂度和重建质量上均优于传统编解码器,且具备更高的灵活性。
如何实现低码率下的高保真压缩?
通过动态参考帧和深度视频生成模型的结合,该方案在低码率条件下实现高保真人脸视频的实时压缩。
未来该方案的扩展方向是什么?
未来可将该框架拓展至各类2D/3D视频的低码率高保真压缩,并探索生成式替代传统编解码器中的预测模块。
