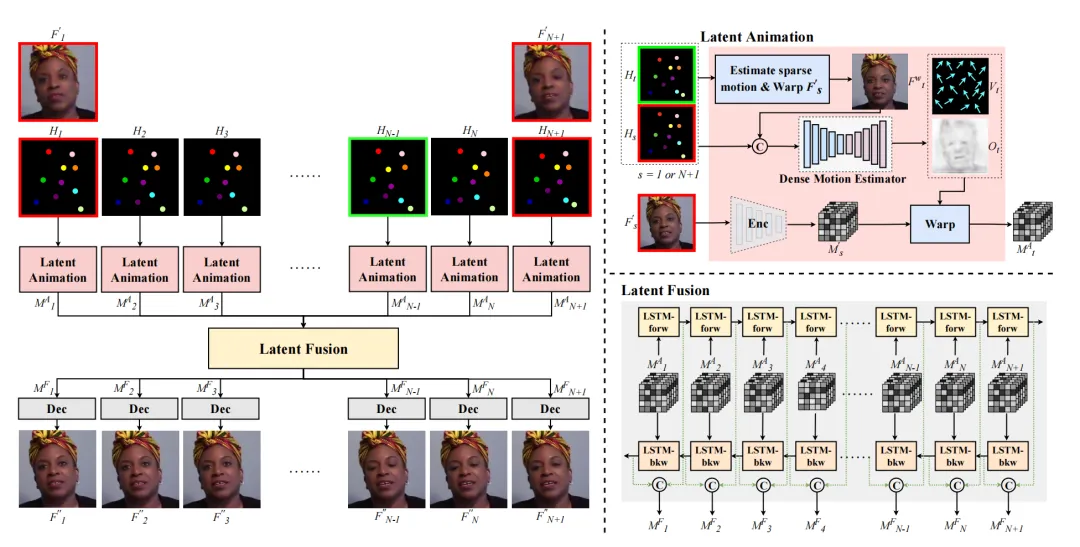
本文提出了一种混合压缩方案,结合传统编码与生成式压缩技术,实现低码率下高保真人脸视频的实时压缩。该方法利用动态参考帧和深度视频生成模型,克服了静态参考帧的局限性,显著提升了视频重建质量和编码效率,适用于社交媒体和实时通信场景。
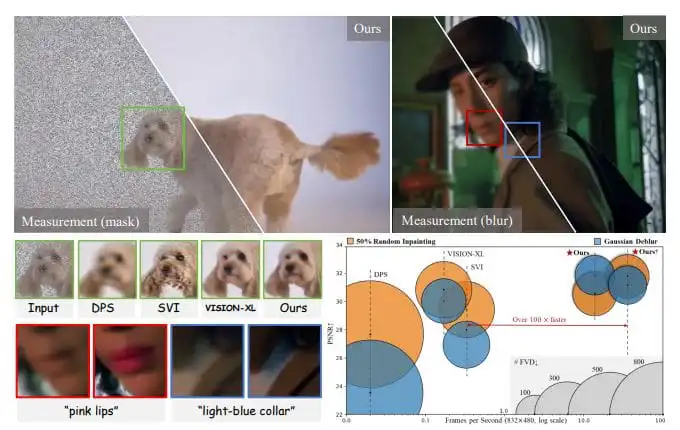
研究团队开发了InstantViR框架,成功解决了实时高质量视频重建的难题。该系统通过简化视频扩散模型,实现每秒超过35帧的处理速度,重建质量优于现有技术,为视频会议和直播等应用带来了新机遇。
本研究提出了一种动态记忆预测框架,解决了现有视频重建方法在复杂场景下对多参考帧的忽视问题。该框架通过引用帧记忆引擎和双向目标预测网络,提高了细粒度视频目标跟踪的精度和鲁棒性,实验结果表明其优于现有自监督技术。
同济大学等机构的研究提出了NeuroClips框架,利用fMRI数据重建高保真视频。该方法有效解决了fMRI低时间分辨率和视频重建控制不足的问题,显著提升了重建效果,增强了神经科学的可解释性。
本研究提出了一种新的4D高斯溅射算法,有效解决了动态场景合成中单目视频的过拟合问题,并通过引入不确定性感知正则化显著提升了视频重建性能。
本研究探讨了脉冲神经网络(SNN)的训练方法,提出了多种新算法和框架,提升了音频压缩、视频重建和语音识别等任务的性能,强调了稀疏脉冲编码的优势及其在复杂时间信息处理中的应用潜力。
本研究提出多种基于变压器的模型,旨在提升医学图像分割、高光谱解混合、视频重建和人体姿态估计等任务的性能。通过创新模块和框架,如混合变压器 U-Net 和 3D 卷积-Transformer 混合模块,实验结果表明这些方法在各自领域优于现有技术,展现出广泛的应用潜力。
本文介绍了多种基于事件相机的深度学习方法,如E2HQV、eSL-Net和HyperE2VID,旨在提升图像和视频重建质量。研究表明,这些方法在真实世界数据集上表现优异,超越了现有技术,具有更好的重建质量和更短的推理时间。
本文介绍了Mind-Video模型,该模型通过对抗性指导从fMRI数据中重建高质量视频,性能比现有模型提高了45%。研究还提出了NeuroCine框架,解决了fMRI数据中的噪声和冗余问题,显著提升了视频重建效果。该方法在多个公开数据集上测试,展现出良好的生物合理性和可解释性,推动了对人脑视觉处理的理解。
完成下面两步后,将自动完成登录并继续当前操作。