

💡
原文英文,约500词,阅读约需2分钟。
📝
内容提要
百度在Hugging Face发布了PP-OCRv5,这是一种高效的光学字符识别模型,专注于文本识别,支持多语言,适合边缘部署。尽管对其多语言能力有疑虑,但在手写和印刷文本的基准测试中表现优异。
🎯
关键要点
- 百度在Hugging Face发布了PP-OCRv5,是一种高效的光学字符识别模型,专注于文本识别。
- PP-OCRv5与大型视觉语言模型不同,专为准确性、效率和速度而设计。
- 该模型解决了OCR中的定位和边界框准确性问题,避免了生成虚假内容的情况。
- PP-OCRv5参数仅为0.07亿,适合在CPU和资源受限的设备上部署。
- 在OmniDocBench基准测试中,PP-OCRv5在手写和印刷文本识别中表现优异,支持五种书写类型和超过40种语言。
- 社区对其多语言能力提出质疑,认为目前仅限于英语和中文。
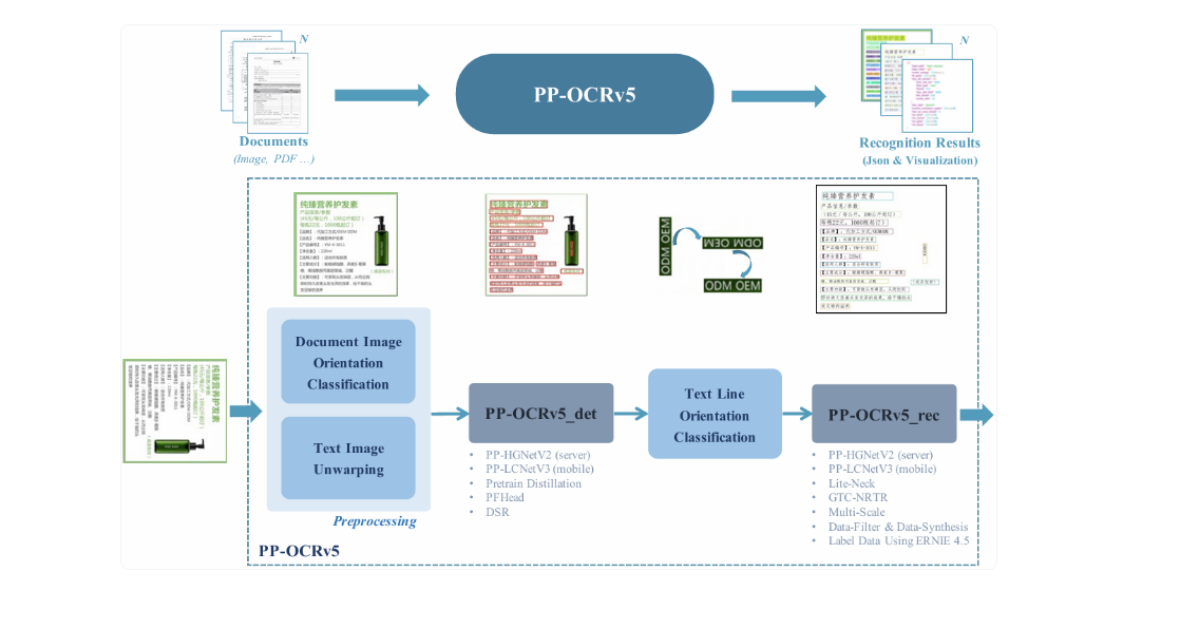
- PP-OCRv5的两阶段管道包括图像预处理、文本检测、文本方向分类和文本识别。
- 该模型的模块化设计使其更轻量,易于针对特定用例进行微调。
- Hugging Face Spaces上提供了演示,用户可以上传PDF或图像并实时获取OCR输出。
➡️
