
Agent设计模式——第 14 章:知识检索(RAG)
内容提要
知识检索(RAG)增强了大语言模型(LLM)的能力,使其能够实时访问外部信息,克服静态训练数据的局限。RAG通过检索相关信息并整合到生成的响应中,提高了准确性和可信度,广泛应用于企业搜索和客户支持等领域。
关键要点
-
知识检索(RAG)增强了大语言模型(LLM)的能力,使其能够实时访问外部信息。
-
RAG 通过检索相关信息并整合到生成的响应中,提高了准确性和可信度。
-
RAG 允许 LLM 访问最新信息,克服了静态训练数据的限制。
-
RAG 通过语义搜索理解用户意图,提供更准确的答案。
-
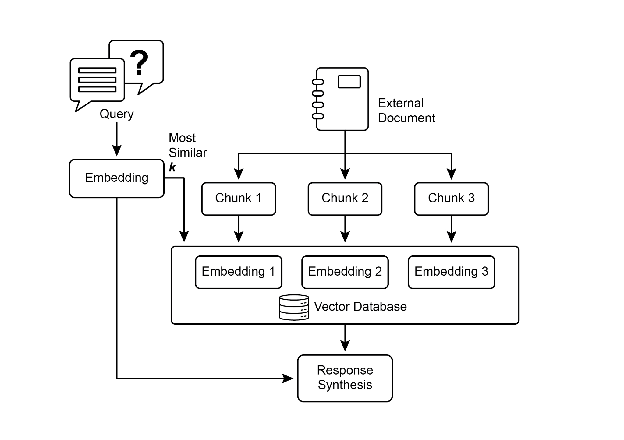
嵌入是文本的数值表示,帮助捕捉文本片段的语义含义和关系。
-
文本相似度和语义相似度在 RAG 中用于找到与用户查询最相关的信息。
-
文档分块将大型文档分解为小块,以提高检索效率。
-
向量数据库专门用于存储和查询嵌入,支持语义搜索。
-
RAG 的挑战包括信息分散、检索质量和知识库的维护。
-
GraphRAG 利用知识图谱回答复杂查询,提供更准确的上下文。
-
Agentic RAG 引入推理层,主动验证和协调检索的信息,确保更可靠的答案。
-
RAG 的实际应用包括企业搜索、客户支持和个性化推荐。
-
RAG 使 LLM 能够生成基于可验证事实的响应,增强了信任和实用性。
延伸解读
RAG的实际应用场景
知识检索(RAG)在多个行业中展现出广泛的应用潜力,尤其是在企业搜索和客户支持领域。通过整合内部文档,RAG能够为员工提供准确的政策信息,或为客户提供一致的支持响应。这种能力不仅提高了工作效率,还减少了人工干预的需求,适用于需要实时和准确答案的场景。
RAG的挑战与局限性
尽管RAG模式具有显著优势,但其实施也面临挑战。信息的分散性可能导致检索不完整,影响答案的准确性。此外,维护知识库的更新和质量也是一项复杂的任务,可能增加系统的延迟和运营成本。因此,在使用RAG时,需关注这些潜在的风险和局限性。
Agentic RAG的优势与复杂性
Agentic RAG通过引入推理层,显著提高了信息检索的可靠性。它不仅能验证信息的质量,还能协调不同来源的知识,确保最终答案的准确性。然而,这种复杂性也带来了更高的实施成本和潜在的延迟,因此在设计系统时需权衡其带来的好处与复杂性。
延伸问答
知识检索(RAG)如何增强大语言模型的能力?
知识检索(RAG)使大语言模型能够实时访问外部信息,克服静态训练数据的局限,从而提高输出的准确性和可信度。
RAG的工作原理是什么?
RAG通过在生成响应前检索相关信息并将其整合到提示中,允许大语言模型提供更准确和可验证的答案。
RAG在企业搜索中的应用有哪些?
RAG可以用于开发内部聊天机器人,利用公司文档响应员工查询,提高信息检索的效率和准确性。
RAG面临哪些挑战?
RAG的挑战包括信息分散、检索质量、知识库维护的复杂性,以及需要定期更新以保持信息的准确性。
什么是Agentic RAG,它有什么优势?
Agentic RAG引入了推理层,能够主动验证和协调检索的信息,从而提供更准确和可靠的答案。
RAG如何减少生成虚假信息的风险?
RAG通过将响应建立在可验证的数据上,减少了生成虚假信息的风险,确保答案的准确性。
