
大模型缓存技术工程指南(上):从价格信号到推理缓存机制
内容提要
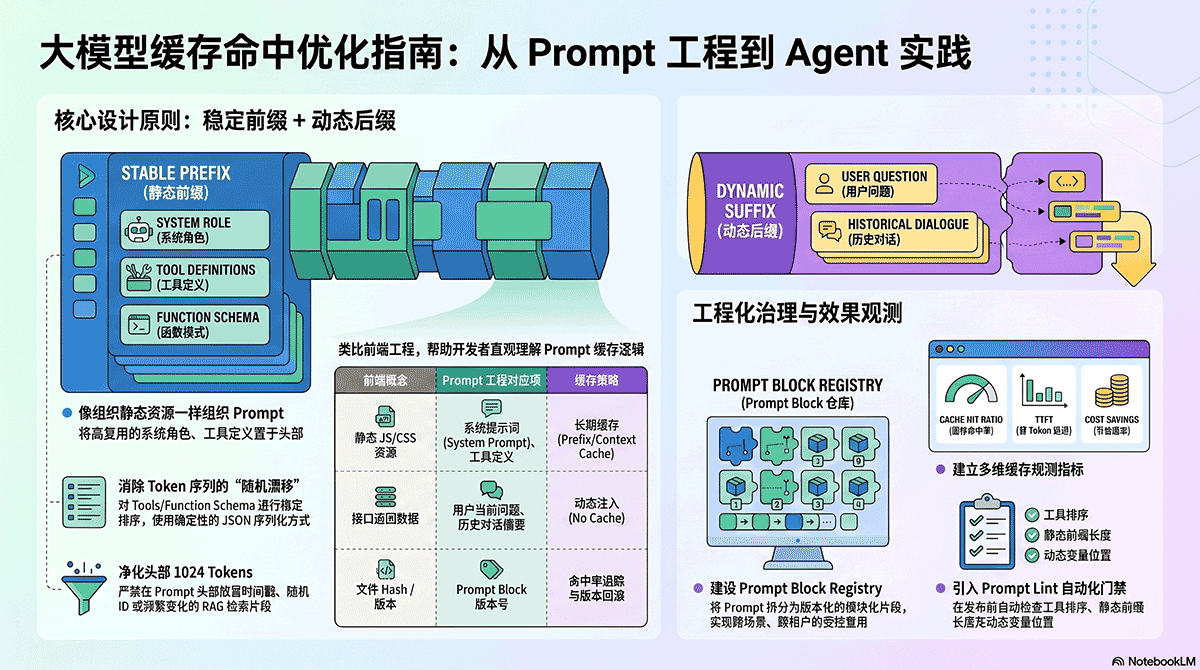
大模型缓存技术包括KV Cache、Prompt Cache和Prefix Cache等,旨在提高生成效率和降低成本。KV Cache避免重复计算,Prompt Cache和Prefix Cache用于跨请求复用相同前缀。应用层的Semantic Cache和Response Cache可以复用历史答案,减少模型调用。本文探讨了缓存机制的设计、成本测算及常见误区,强调了缓存对大模型推理的重要性。
关键要点
-
大模型缓存技术包括KV Cache、Prompt Cache和Prefix Cache等,旨在提高生成效率和降低成本。
-
KV Cache避免重复计算,Prefill阶段生成并保存K/V,Decode阶段复用历史K/V。
-
PagedAttention是KV Cache的显存管理方案,减少显存碎片并支持prefix block复用。
-
Prompt Cache和Prefix Cache用于跨请求复用相同前缀,优化重复输入的成本。
-
应用层的Semantic Cache和Response Cache可以复用历史答案,减少模型调用。
-
缓存机制的设计、成本测算及常见误区对大模型推理至关重要。
-
工程团队需关注缓存命中率、显存占用和成本测算,以优化大模型的使用。
延伸解读
缓存技术的多层次结构
大模型缓存技术分为多个层次,包括模型推理层、推理服务层、API产品层和应用层。每一层的缓存策略解决不同的问题,工程团队需根据具体需求选择合适的缓存类型,以优化性能和成本。
显存管理的重要性
KV Cache的显存占用与模型的层数、上下文长度和并发请求数量密切相关。工程团队应关注显存管理,采用PagedAttention等技术来减少显存碎片,提高系统的并发处理能力。
缓存命中率的影响因素
缓存命中率直接影响模型的性能和成本。工程团队需关注Prompt Cache和Prefix Cache的设计,确保稳定的前缀输入,以提高缓存命中率,从而降低重复计算的开销。
应用层缓存的风险
在应用层使用Semantic Cache和Response Cache时,需注意内容的时效性和权限问题。错误的缓存可能导致过期信息被复用,影响用户体验,因此应建立有效的失效策略和权限校验机制。
延伸问答
大模型缓存技术的主要类型有哪些?
大模型缓存技术主要包括KV Cache、Prompt Cache、Prefix Cache、Semantic Cache和Response Cache等。
KV Cache是如何提高生成效率的?
KV Cache通过避免重复计算历史token的K/V,允许在生成过程中复用已计算的结果,从而提高生成效率。
Prompt Cache和Prefix Cache有什么区别?
Prompt Cache主要用于跨请求复用相同的前缀,而Prefix Cache则是具体实现的术语,关注如何复用已经计算的KV cache blocks。
PagedAttention在KV Cache中起什么作用?
PagedAttention通过将KV Cache切分为固定大小的block,减少显存碎片并支持prefix block的复用,从而提高显存管理效率。
如何评估大模型缓存的成本效益?
评估大模型缓存的成本效益需要考虑输入token成本、缓存写入和读取成本、输出token成本等多个因素。
Semantic Cache和Response Cache的主要区别是什么?
Semantic Cache基于语义相似度复用答案,而Response Cache则是完全相同请求的结果缓存,主要用于FAQ等场景。
