
内容提要
本文探讨了vivo在构建Pulsar监控系统中的实践,指出Pulsar在指标上优于Kafka,并提出了监控告警系统的架构与优化方案,提升了用户体验和运维效率,推动了Pulsar在vivo的应用。
关键要点
-
vivo在构建Pulsar监控系统中实践,Pulsar在指标上优于Kafka。
-
Pulsar支持上报分区粒度指标,而Kafka没有,导致Pulsar的指标量级更大。
-
使用Prometheus作为Pulsar指标的采集、存储和查询方案,但存在存储和查询的局限性。
-
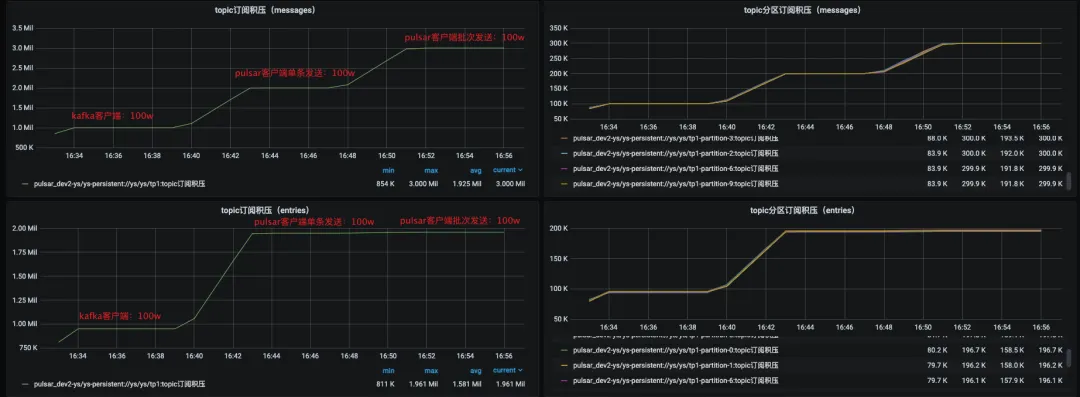
Pulsar的订阅积压指标单位是entry,影响用户体验,需优化为以消息条数为单位。
-
监控告警系统架构中,adaptor负责服务发现和指标转发,Druid用于数据分析。
-
优化Prometheus参数以减少内存和CPU消耗,提升监控系统性能。
-
Pulsar的bundle指标用于调优负载均衡策略,提供流量分布和连接数量信息。
-
解决了kop消费延迟指标无法上报的问题,提升了监控系统的可靠性。
-
尽管解决了一些问题,Pulsar监控链路仍存在单点瓶颈,未来发展面临挑战。
延伸问答
Pulsar相比Kafka有哪些优势?
Pulsar在指标上优于Kafka,支持上报分区粒度指标,而Kafka没有,导致Pulsar的指标量级更大。
vivo是如何优化Pulsar监控系统的?
vivo通过优化Prometheus参数、改进订阅积压指标单位、增加bundle指标等方式提升了Pulsar监控系统的性能和用户体验。
Prometheus在Pulsar监控中存在哪些局限性?
Prometheus的时序数据库不是分布式的,受单机资源限制,且在存储和查询时消耗大量内存和CPU。
Pulsar的订阅积压指标是如何改进的?
Pulsar的订阅积压指标单位由entry改为消息条数,以便用户更方便地判断延迟情况。
vivo在Pulsar监控系统中使用了哪些技术?
vivo使用了Prometheus进行指标采集,并结合Druid进行数据分析,同时开发了adaptor进行服务发现和指标转发。
Pulsar监控链路面临哪些挑战?
尽管解决了一些问题,Pulsar监控链路仍存在单点瓶颈等问题,未来发展面临挑战。
