
SemanticKernel/C#:检索增强生成(RAG)简易实践
原文中文,约4100字,阅读约需10分钟。
📝
内容提要
检索增强生成(RAG)是一种结合检索技术与生成模型的方法,主要用于自然语言处理任务。它通过从外部知识库检索信息并与输入文本结合,生成更准确的输出,特别适用于需要背景知识的任务。RAG提升了大语言模型在回答基于私有文档问题时的准确性和可解释性,采用了向量化和数据库存储技术。
🎯
关键要点
-
检索增强生成(RAG)是一种结合检索技术和生成模型的方法,主要用于自然语言处理任务。
-
RAG模型通过从外部知识库中检索信息并与输入文本结合,以生成更准确的输出。
-
RAG特别适用于需要大量背景知识的任务,如专业领域的问答系统。
-
RAG提升了大语言模型在回答基于私有文档问题时的准确性和可解释性。
-
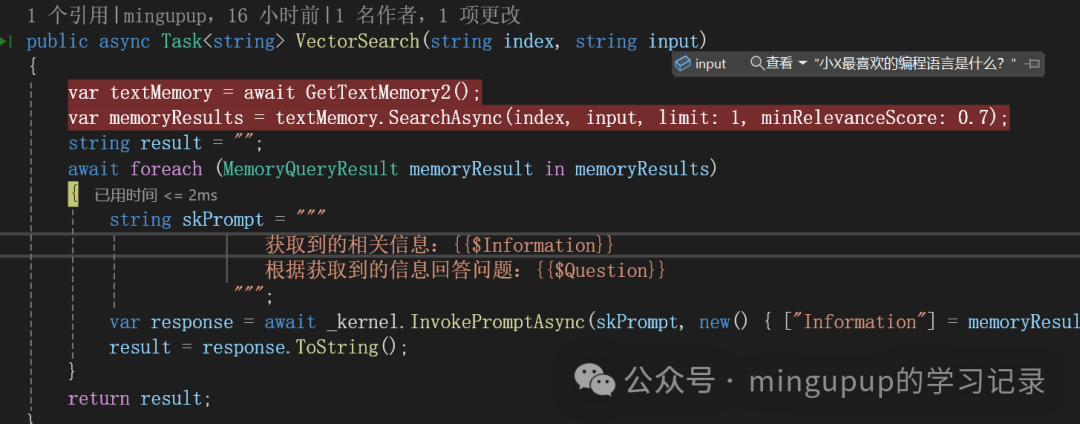
实现RAG的思路是将文本转化为向量,存入数据库,并基于输入查询的向量进行检索。
-
使用SQLite存储生成的向量,并通过余弦相似度检索最相关的片段。
-
下一步探索方向包括在本地运行大语言模型与嵌入模型的结合。
❓
延伸问答
检索增强生成(RAG)的主要功能是什么?
RAG结合了检索技术和生成模型,主要用于自然语言处理任务,通过从外部知识库检索信息生成更准确的输出。
RAG如何提高大语言模型的准确性?
RAG通过检索外部知识并将其与输入文本结合,明确指出生成文本与外部知识的关联,从而提升准确性和可解释性。
RAG适用于哪些类型的任务?
RAG特别适用于需要大量背景知识的任务,如专业领域的问答系统和对话代理。
如何实现RAG模型的向量化?
实现RAG模型的向量化需要将文本转化为向量,存入数据库,并基于输入查询的向量进行检索。
在RAG中如何使用SQLite存储向量?
在RAG中,可以使用SQLite作为存储向量的数据库,通过将生成的向量保存到SQLite数据库中进行管理。
RAG的下一步探索方向是什么?
下一步探索方向包括在本地运行大语言模型与嵌入模型的结合,以及使用Ollama等平台的集成。
🏷️
