
微软发布 VibeVoice-ASR:一种统一的语音转文本模型,旨在一次性处理长达 60 分钟的音频
内容提要
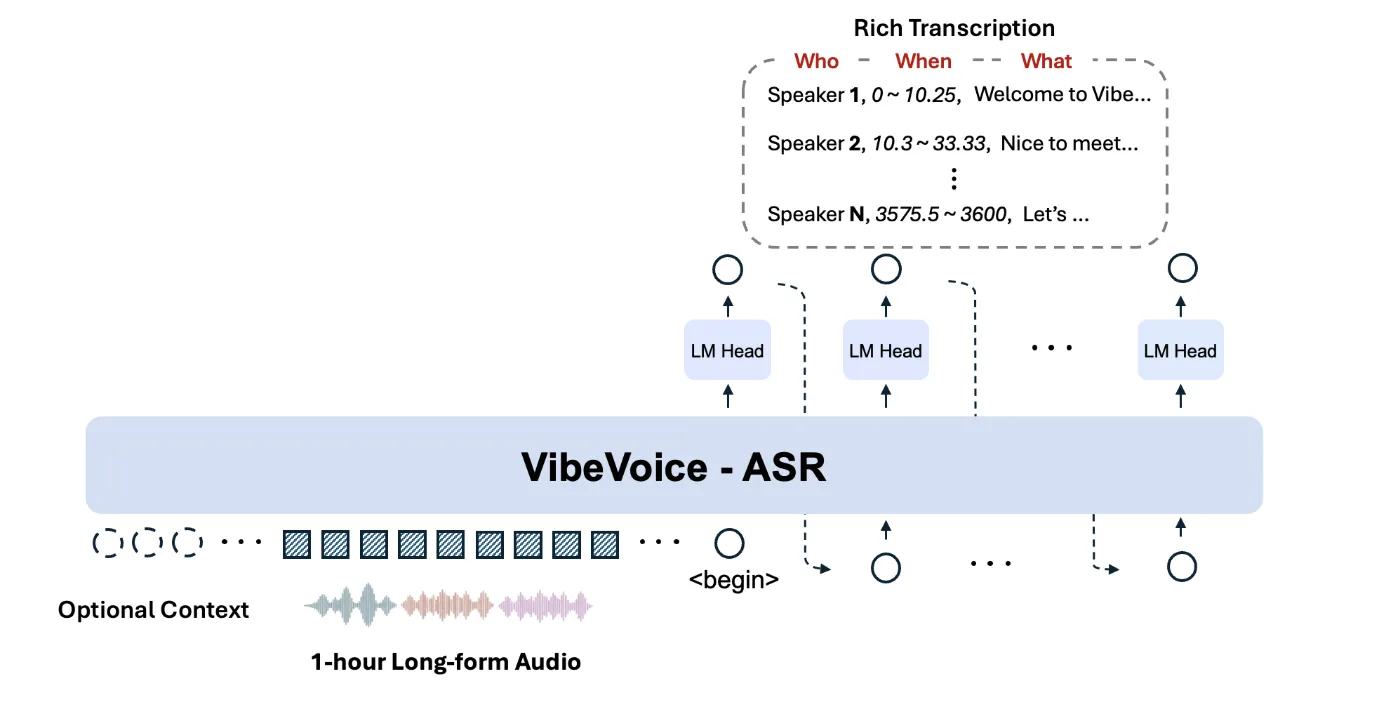
微软推出了VibeVoice-ASR,一个开源的语音转文本模型,支持最长60分钟的音频处理,输出结构化文本,包括“谁”、“何时”、“什么”。该模型允许用户自定义热词,以提高识别准确性,适合会议记录和长时间通话。
关键要点
-
微软推出了VibeVoice-ASR,一个开源的语音转文本模型。
-
该模型支持最长60分钟的音频处理,输出结构化文本,包括“谁”、“何时”、“什么”。
-
VibeVoice-ASR允许用户自定义热词,以提高识别准确性,适合会议记录和长时间通话。
-
模型在64K标记长度预算内接收长达60分钟的连续音频输入,保持说话人身份和主题上下文。
-
自定义热词功能使用户能够针对特定领域调整识别过程,无需重新训练模型。
-
模型联合执行自动语音识别、人声分割和时间戳功能,返回结构化输出。
-
使用DER、cpWER和tcpWER评估模型在多说话人长篇数据上的表现。
-
VibeVoice-ASR在VibeVoice开源堆栈中以MIT许可证发布,附带官方权重和微调脚本。
延伸解读
长音频处理的优势
VibeVoice-ASR能够一次性处理长达60分钟的音频,这在传统的语音识别系统中是难以实现的。许多系统需要将音频分割成短片段,这可能导致上下文丢失。而VibeVoice-ASR通过64K标记窗口保持了说话人身份和主题的一致性,特别适合会议记录和长时间通话的场景。
自定义热词的实用性
VibeVoice-ASR的自定义热词功能允许用户根据特定领域调整识别过程,提升准确性。这意味着用户可以在不重新训练模型的情况下,针对特定术语进行优化,适用于多种行业应用,如技术支持或产品介绍。
结构化输出的应用前景
该模型的结构化输出包含“谁”、“何时”、“什么”等信息,适合后续处理,如摘要提取和行动项分析。这种输出格式使得用户能够更高效地管理和分析长时间的对话记录,提升工作效率。
延伸问答
VibeVoice-ASR是什么?
VibeVoice-ASR是微软推出的一个开源语音转文本模型,支持最长60分钟的音频处理,输出结构化文本。
VibeVoice-ASR如何处理长时间音频?
该模型在64K标记长度预算内接收长达60分钟的连续音频输入,保持说话人身份和主题上下文。
用户如何自定义VibeVoice-ASR的热词?
用户可以提供特定的热词,如产品名称或技术术语,模型会根据这些热词调整识别过程,无需重新训练。
VibeVoice-ASR的输出格式是什么样的?
模型返回结构化的转录文本,包含“谁”、“何时”、“什么”等信息,适合下游处理。
VibeVoice-ASR的评估指标有哪些?
评估指标包括DER(说话人分割错误率)、cpWER和tcpWER,主要用于多说话人对话场景。
VibeVoice-ASR的应用场景有哪些?
该模型适合用于会议记录、讲座录音和长时间通话等任务。
