飞书、钉钉、企业微信和谷歌等平台推出了专为AI Agent设计的命令行工具,标志着软件交互方式的转变。这些CLI工具通过结构化文本命令,提高了AI与软件的交互效率和安全性,解决了AI操作中的认知接口问题。CLI设计强调结构化输出、自省能力和无交互模式,确保AI可靠执行任务并处理异常,推动AI在企业中的应用。
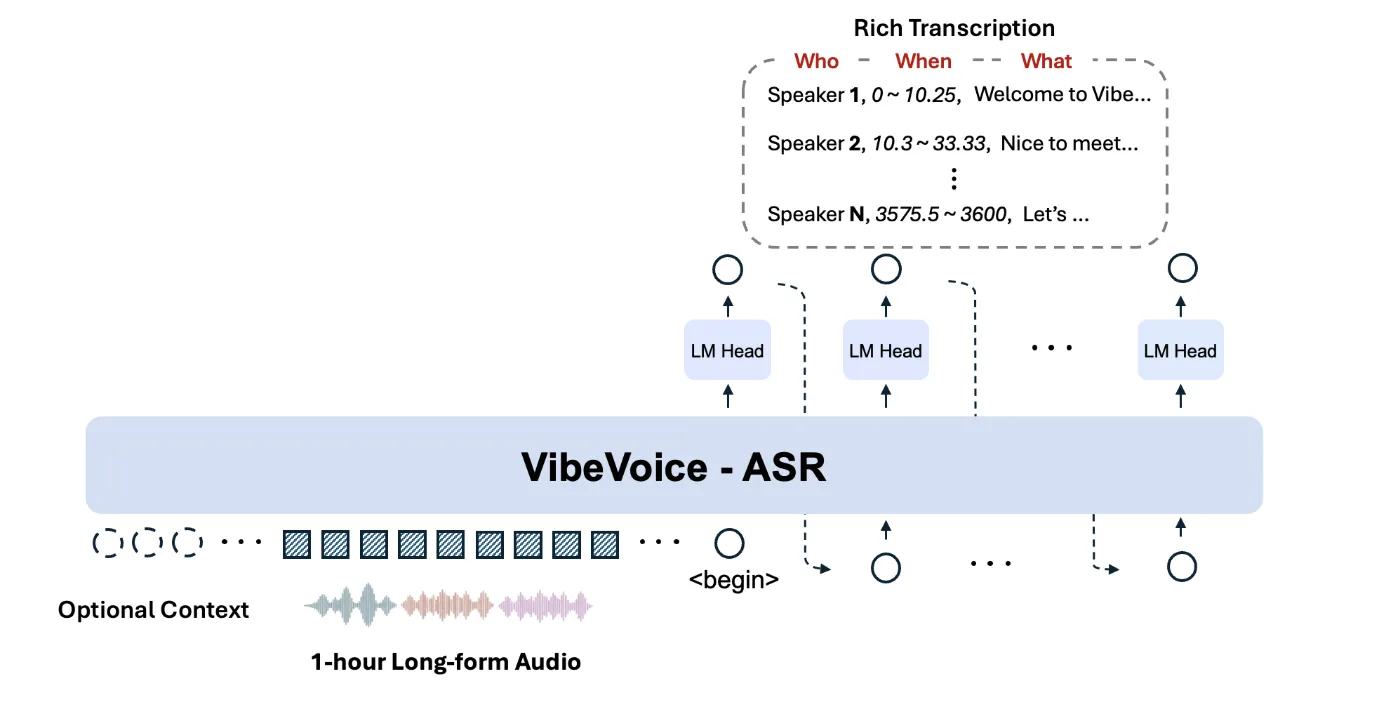
微软推出了VibeVoice-ASR,一个开源的语音转文本模型,支持最长60分钟的音频处理,输出结构化文本,包括“谁”、“何时”、“什么”。该模型允许用户自定义热词,以提高识别准确性,适合会议记录和长时间通话。
AWK是Linux内置的文本处理工具,专注于结构化文本。它逐行读取文件,通过字段处理数据,支持简单编程逻辑,常用于条件过滤和字符串处理,适合处理日志和CSV文件,提供高效的文本分析能力。
olmOCR是一个开源Python工具包,旨在将PDF转换为结构化文本,保持自然阅读顺序。它基于7B视觉语言模型,适合处理大规模文档。安装要求包括RTX 4090或A6000 GPU、50-100GB存储和至少8GB内存,支持通过NodeShift等云平台部署,提供高效的文档解析和文本提取功能。
本研究提出了一种新方法,将通用大语言模型(LLMs)应用于电子健康记录(EHR)编码。通过将病人记录序列化为结构化Markdown文本,LLM在15个临床预测任务中表现优异,超越传统模型,展现了在临床预测中的潜力与可扩展性。
本文介绍了提升提示效果的关键方法,包括结构化文本、分解复杂请求、引导模型推理和组合响应。结构化提示有助于模型理解任务,分解请求提高准确性,逐步引导模型思考可获得更可靠的答案。
本文介绍了AutoPLC,一种基于大型语言模型的自动化代码生成方法,旨在解决可编程逻辑控制器中结构化文本编码的标准化问题。AutoPLC通过知识库和检索模块生成符合供应商需求的ST代码,并利用适应性检查器提升代码质量。实验结果显示其在工业应用中表现优越。
本文研究了结构化文本本地化,提出了高质量的多语种数据集和翻译模型。实验表明,使用XML标签可以提高翻译的精确度。同时,探讨了低资源语言的机器翻译支持、缩略语消歧及大型语言模型在翻译中的应用,提出了一种新的机器翻译范式,特别适用于濒危语言。
本文介绍了多个研究成果,包括新系统ASET用于结构化文本探索、三阶段文件问答方法、图像检索基准测试、少样本文档级关系抽取基准测试FREDo,以及针对法律领域的FIR数据集。这些研究旨在提升信息提取和问答系统的性能,解决非结构化数据问题。
完成下面两步后,将自动完成登录并继续当前操作。