
Google AI 推出 Learn-by-Interact:一种以数据为中心的自适应高效 LLM 代理开发框架
内容提要
大型语言模型驱动的自主代理研究显示出提升人类生产力的潜力,但在效率和可靠性方面仍存在挑战。研究人员提出了“通过互动学习”框架,自动合成高质量数据,显著提升模型性能,减少对人工注释的依赖,为开发更可靠的自适应代理提供了新思路。
关键要点
-
大型语言模型驱动的自主代理研究显示出提升人类生产力的潜力。
-
自主代理旨在协助完成编码、数据分析和网页导航等任务。
-
当前系统在效率和可靠性方面仍面临挑战,尤其是在适应新环境方面。
-
缺乏高质量、特定于环境的数据集是主要限制之一。
-
传统技术依赖人工注释数据,存在成本高和效率低的问题。
-
谷歌和香港大学提出了“通过互动学习”框架,解决了上述限制。
-
互动学习框架允许代理生成任务指令并自主交互,确保数据高质量。
-
框架使用自我指导创建任务指令,并通过反向构造确保一致性。
-
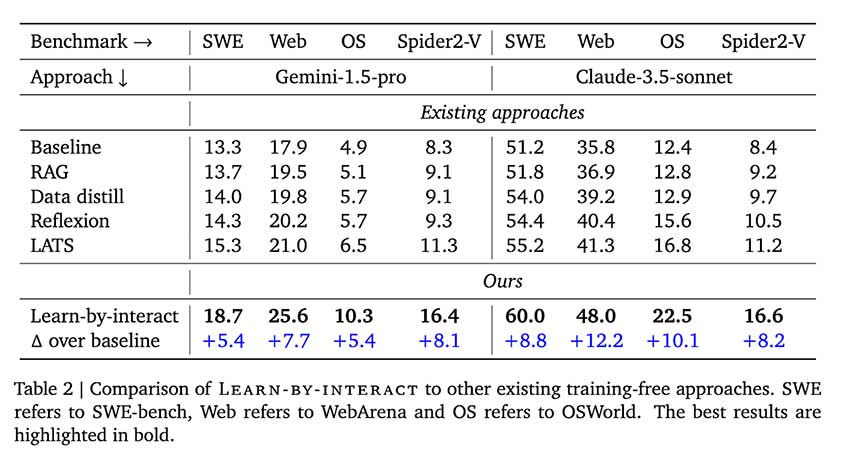
Learn-by-Interact在多个基准测试中表现优于传统方法,准确率显著提高。
-
该框架优化推理效率,减少计算资源消耗,推动自适应代理的发展。
-
Learn-by-Interact为合成高质量数据提供了可扩展性,减少对人工注释的需求。
-
框架引入后向构造和高级检索技术,提高了自主代理的效率和适应性。
延伸解读
自主代理的应用前景
大型语言模型驱动的自主代理在编码、数据分析和网页导航等领域展现出广泛的应用潜力。随着Learn-by-Interact框架的引入,这些代理能够更好地适应动态环境,提升工作效率,帮助用户专注于更具创造性的任务。
互动学习的优势
Learn-by-Interact框架通过自动合成高质量数据,显著减少了对人工注释的依赖。这种方法不仅提高了数据的质量和一致性,还优化了推理效率,降低了计算资源的消耗,为自主代理的开发提供了新的可能性。
面临的挑战与限制
尽管Learn-by-Interact在多个基准测试中表现优异,但仍需关注其在特定环境下的适应能力。未来的研究应继续探索如何进一步提升模型在复杂场景中的表现,以确保其在实际应用中的可靠性。
延伸问答
Learn-by-Interact 框架的主要功能是什么?
Learn-by-Interact 框架允许代理生成任务指令并自主交互,从而自动合成高质量数据,提升模型性能。
该框架如何解决传统方法的限制?
该框架通过减少对人工注释的依赖,自动生成高质量数据,优化推理效率,解决了传统方法的高成本和低效率问题。
Learn-by-Interact 在基准测试中的表现如何?
在多个基准测试中,Learn-by-Interact 的准确率显著提高,例如在 OSWorld 上准确率从 12.4% 提高到 22.5%。
互动学习框架的关键过程是什么?
互动学习框架的关键过程包括自我指导创建任务指令、生成交互轨迹和反向构造以确保数据一致性。
Learn-by-Interact 如何提高自主代理的效率?
该框架通过减少语言模型调用和标记数量,优化推理过程,从而提高自主代理的效率。
该框架对未来 LLM 代理的开发有什么影响?
Learn-by-Interact 为开发更可靠的 LLM 代理提供了新思路,减少了对人工注释的需求,并在实际应用中实现了卓越性能。
