
Airbnb如何构建一个用于PB级数据的键值存储
内容提要
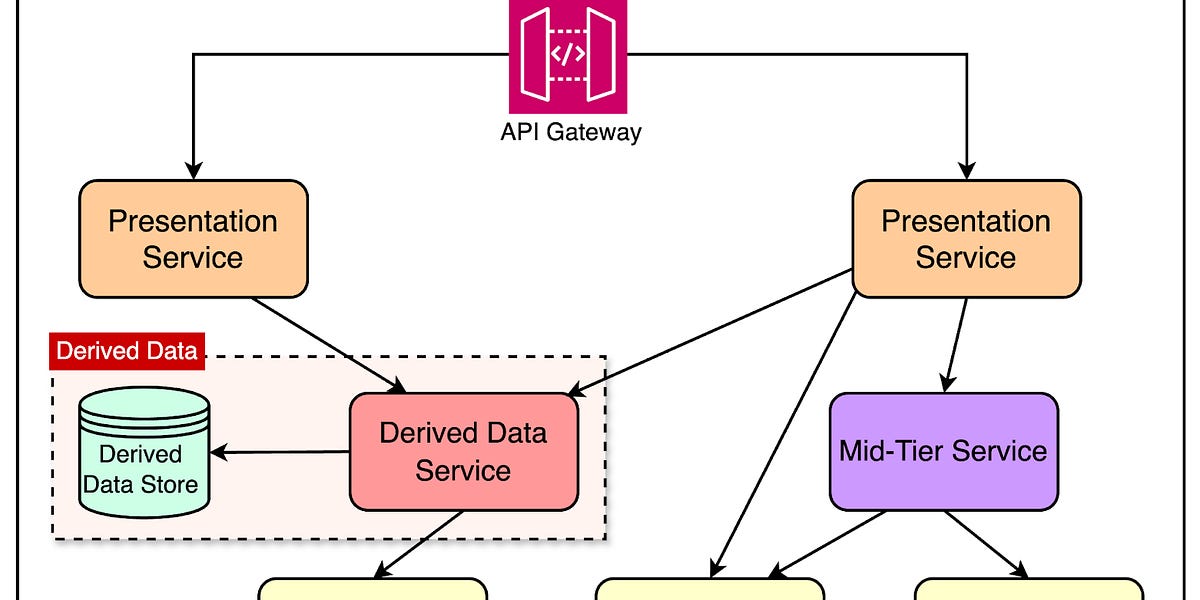
Airbnb的Mussel是一个高效管理派生数据的关键值存储系统,采用分区管理、无领导复制和统一存储引擎,解决了可扩展性和低延迟问题,支持实时和批量数据,确保高可用性和快速访问,成为数据基础设施的核心。
关键要点
-
Airbnb的Mussel是一个高效管理派生数据的关键值存储系统。
-
Mussel采用分区管理、无领导复制和统一存储引擎,解决了可扩展性和低延迟问题。
-
派生数据是从大量离线数据集或实时事件流中计算得出的信息,支持个性化功能。
-
Mussel的架构设计确保了高可用性和快速访问,成为数据基础设施的核心。
-
Mussel的演变经历了多个阶段,包括HFileService和Nebula。
-
HFileService是一个统一的只读关键值存储,解决了数据管理和快速访问的问题,但不支持实时更新。
-
Nebula结合了批处理和实时数据,使用DynamoDB和HFileService,但维护复杂且合并过程效率低下。
-
Mussel通过增加分区数量、使用Kafka进行无领导复制和统一存储引擎来优化性能。
-
Mussel支持增量数据加载,显著提高了效率,减少了操作成本。
-
Mussel在生产环境中管理约130TB的数据,提供超过99.9%的可用性,处理超过800,000 QPS的读取请求。
延伸解读
派生数据的重要性
派生数据是从大量离线数据集或实时事件流中计算得出的信息,对于个性化功能至关重要。Airbnb利用派生数据来提升用户体验,因此,确保高效访问和管理这些数据是其技术架构的核心。
Mussel的架构优势
Mussel通过分区管理和无领导复制等技术,显著提高了数据访问的效率和系统的可扩展性。其设计不仅解决了以往系统的性能瓶颈,还确保了高可用性,适应了Airbnb不断增长的数据需求。
技术演变的教训
Airbnb在开发Mussel之前经历了多个存储系统的演变,每个阶段都暴露了不同的技术挑战。HFileService和Nebula的经验教训表明,实时数据处理和系统维护的复杂性是设计新系统时必须考虑的重要因素。
延伸问答
Mussel是什么,它的主要功能是什么?
Mussel是Airbnb开发的一个高效的键值存储系统,主要用于管理派生数据,确保高可用性和快速访问。
Mussel如何解决可扩展性和低延迟问题?
Mussel通过分区管理、无领导复制和统一存储引擎来优化性能,从而解决可扩展性和低延迟问题。
Mussel与之前的HFileService和Nebula相比有什么优势?
Mussel在架构上整合了实时和批量数据,简化了系统,提升了性能,解决了HFileService和Nebula的维护复杂性和效率低下的问题。
Mussel的性能指标如何?
Mussel管理约130TB的数据,提供超过99.9%的可用性,处理超过800,000 QPS的读取请求,平均读取延迟低于8毫秒。
Mussel如何支持增量数据加载?
Mussel通过仅加载增量变化的数据,将每日数据加载量从4TB减少到40-80GB,从而提高了效率和降低了操作成本。
Mussel的未来发展方向是什么?
Airbnb工程团队致力于增强Mussel,以支持读取后写入一致性、自动扩展和基于流量的重新分区等用例。
