

LinkedIn如何为数千个服务构建下一代服务发现系统
💡
原文英文,约3000词,阅读约需11分钟。
📝
内容提要
Monster SCALE Summit是一个虚拟会议,专注于大规模工程和数据密集型应用。来自Discord和Disney等公司的工程师将分享50多场关于分布式数据库和实时处理的演讲。LinkedIn的下一代服务发现系统通过Kafka和xDS协议,解决了Zookeeper的可扩展性和兼容性问题,实现了更高效的数据传播和多语言支持。
🎯
关键要点
- Monster SCALE Summit是一个虚拟会议,专注于大规模工程和数据密集型应用。
- 来自Discord、Disney等公司的工程师将分享50多场关于分布式数据库和实时处理的演讲。
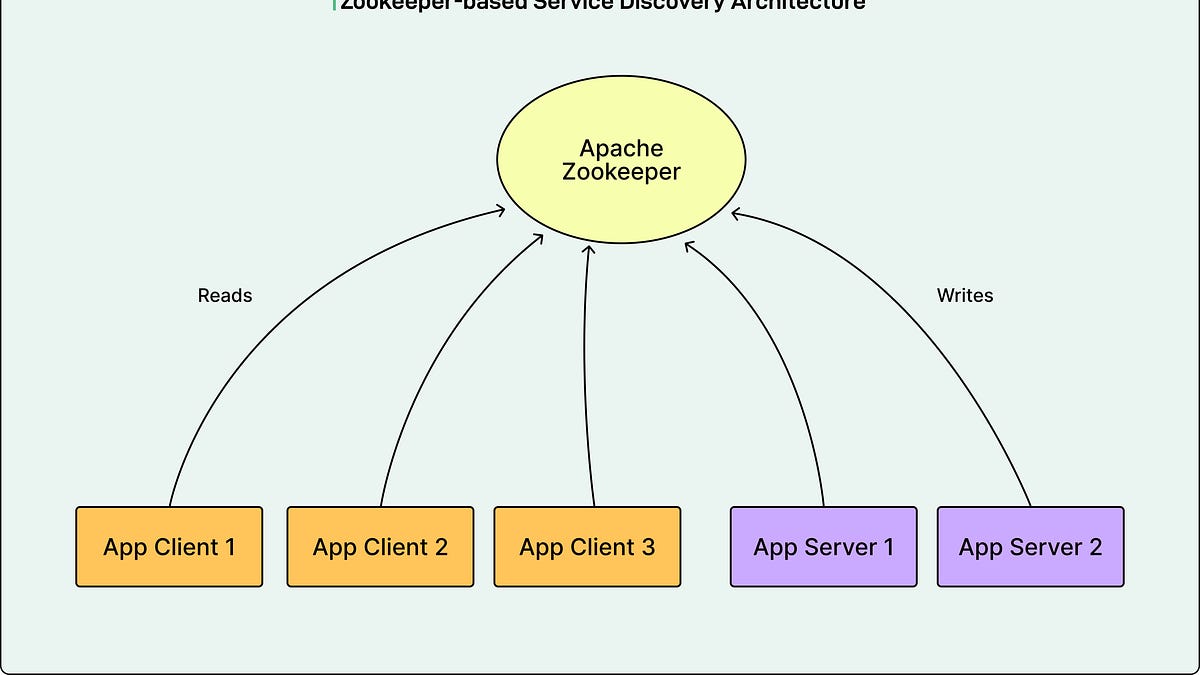
- LinkedIn的下一代服务发现系统通过Kafka和xDS协议解决了Zookeeper的可扩展性和兼容性问题。
- LinkedIn的服务发现系统支持数以万计的微服务之间的高效通信。
- Zookeeper作为控制平面存在可扩展性、兼容性和可扩展性限制。
- 下一代服务发现架构将写入和读取路径分开,使用Kafka处理写入,使用Service Discovery Observer处理读取。
- 新架构优先考虑可用性而非一致性,支持多语言和现代工具。
- 迁移到下一代服务发现系统面临服务发现数据匹配、应用状态复杂性和读写迁移耦合等挑战。
- LinkedIn实施了双模式迁移策略,允许旧系统和新系统同时运行以验证新流程。
- 下一代服务发现系统在数据传播延迟方面实现了显著改进,提升了平台的可靠性和未来创新能力。
➡️
