
优步将内部搜索索引迁移至OpenSearch的基于拉取的摄取框架
内容提要
优步将内部搜索索引系统迁移至OpenSearch,采用基于拉取的摄取框架,以提升实时索引的可靠性和恢复能力,降低维护自家搜索平台的复杂性和成本。新架构通过Kafka或Kinesis缓冲数据,增强吞吐量和稳定性,支持多区域一致性,确保用户获得一致的搜索体验。
关键要点
-
优步将内部搜索索引系统迁移至OpenSearch,采用基于拉取的摄取框架。
-
新架构旨在提升实时索引的可靠性、处理能力和恢复能力,降低维护自家搜索平台的复杂性和成本。
-
优步的搜索基础设施支持乘车发现、配送选择和基于位置的查询,处理近实时的事件流。
-
基于推送的摄取在小规模时有效,但在流量激增和故障时会导致写入丢失和复杂的重试。
-
基于拉取的摄取将责任转移到OpenSearch集群,使用Kafka或Kinesis作为缓冲,增强吞吐量和稳定性。
-
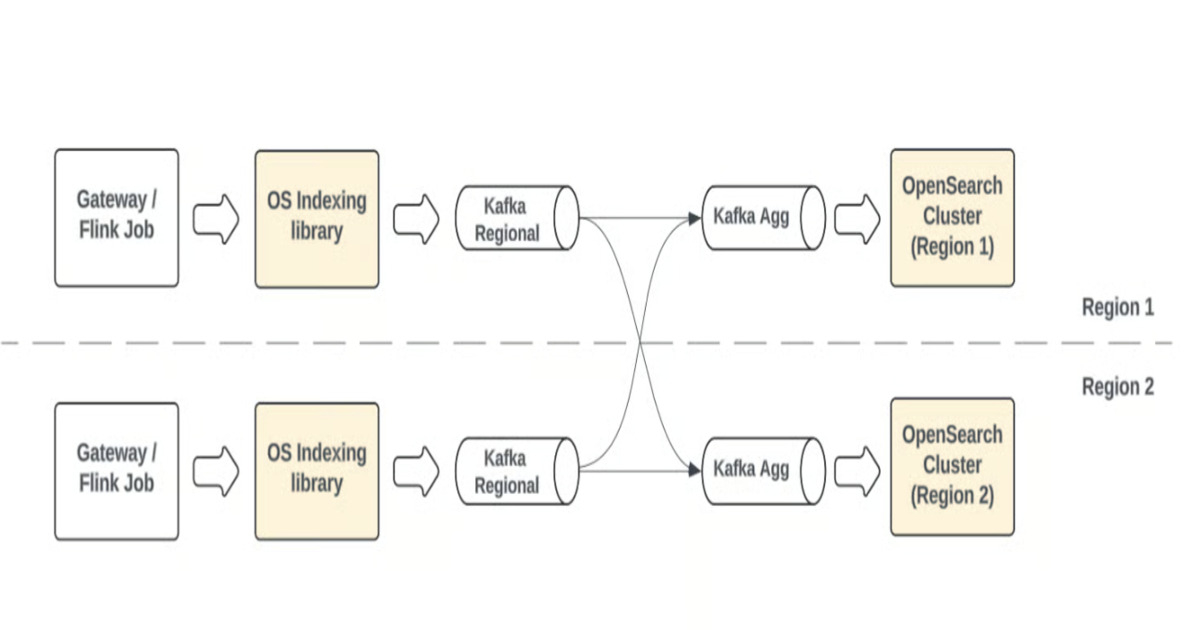
拉取式管道包括多个交互组件,事件被生产到Kafka或Kinesis主题中,确保可预测的重放。
-
拉取式摄取提供细粒度的操作控制,确保消息处理的一致性和可靠性。
-
优步支持两种摄取模式:段复制和全活跃模式,分别在计算成本和可见性上有所不同。
-
拉取式摄取是优步高度可用的多区域搜索架构的核心,确保全球一致性和无缝故障转移。
-
优步正在逐步将所有搜索用例迁移到OpenSearch的拉取式摄取,朝着云原生、可扩展的架构发展。
延伸解读
拉取式摄取的优势
优步采用拉取式摄取框架,显著提升了实时索引的可靠性和恢复能力。这种方式通过将数据从Kafka或Kinesis缓冲,减少了流量激增时的写入丢失风险,确保了系统在高负载下的稳定性。
多区域一致性的保障
优步的新架构支持多区域一致性,确保全球用户在搜索时获得相同的体验。通过将每个区域的OpenSearch集群与全球聚合的Kafka主题连接,优步能够实现冗余和无缝故障转移,增强了系统的可用性。
推送与拉取的比较
推送式摄取在小规模时表现良好,但在流量激增时容易导致问题。相比之下,拉取式摄取通过控制数据流入速率和内部压力,提供了更好的处理能力和一致性,适合优步这样的大规模应用场景。
延伸问答
优步为什么要将搜索索引系统迁移到OpenSearch?
优步迁移到OpenSearch是为了提升实时索引的可靠性、处理能力和恢复能力,同时降低维护自家搜索平台的复杂性和成本。
优步的新架构如何处理数据流?
新架构通过Kafka或Kinesis缓冲数据,增强吞吐量和稳定性,支持多区域一致性,确保用户获得一致的搜索体验。
拉取式摄取与推送式摄取有什么区别?
拉取式摄取将责任转移到OpenSearch集群,使用缓冲区控制数据流,而推送式摄取在流量激增时容易导致写入丢失和复杂的重试。
优步的搜索基础设施支持哪些功能?
优步的搜索基础设施支持乘车发现、配送选择和基于位置的查询,处理近实时的事件流。
优步的拉取式摄取架构有哪些优点?
拉取式摄取提供细粒度的操作控制,确保消息处理的一致性和可靠性,减少索引失败,并简化操作恢复。
优步支持哪些摄取模式?
优步支持段复制和全活跃模式,前者在计算成本上更低但可见性稍有延迟,后者提供更快的可见性但计算成本更高。
