
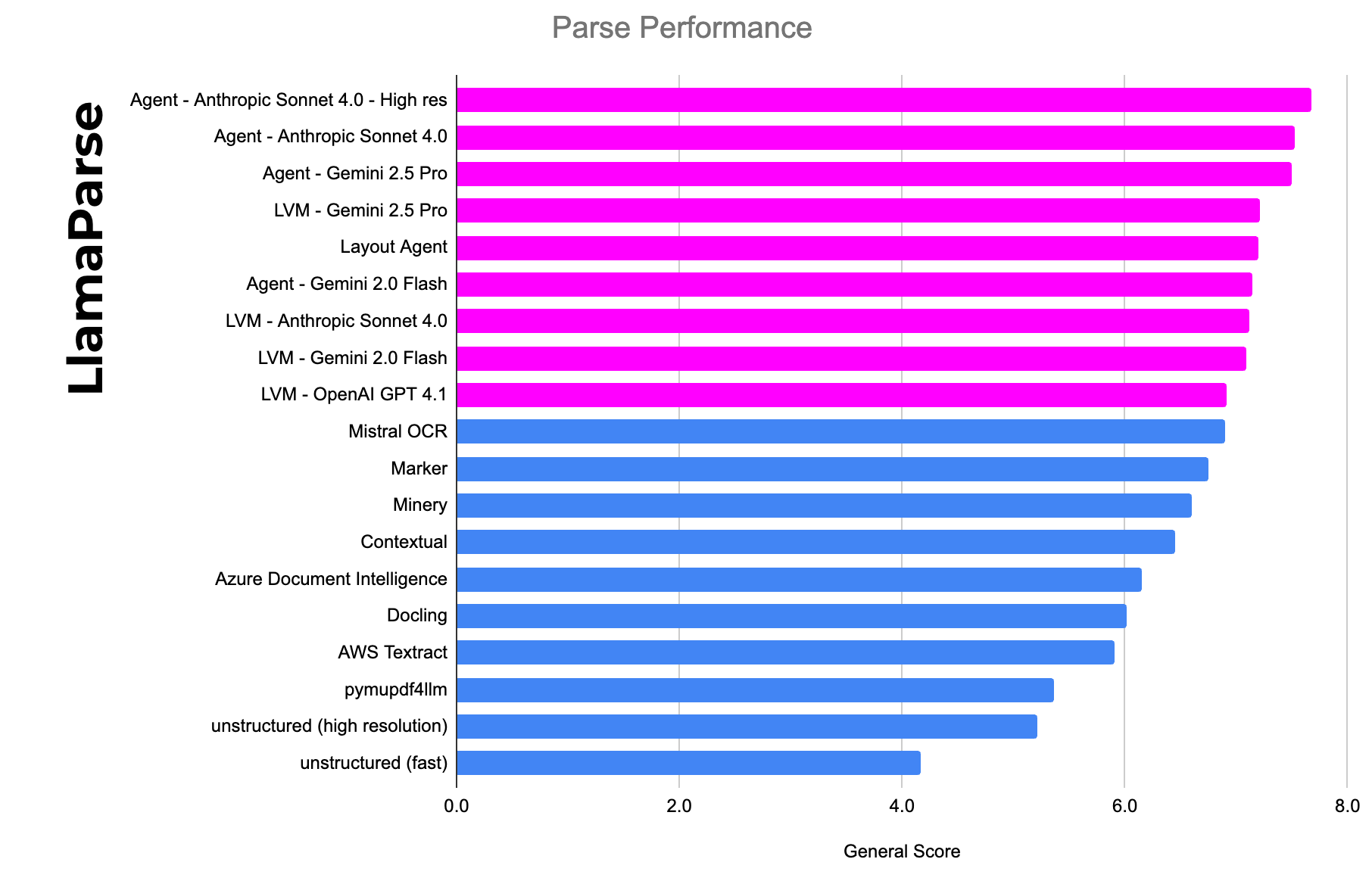
LLM API 并不是完整的文档解析器
内容提要
前沿大语言模型(LLM)在复杂文档处理中的准确性仍有不足,依赖截图的解析方法缺乏企业元数据和信心评分,且维护成本高。LlamaCloud结合LLM与传统解析技术,旨在提高准确性并降低成本,适用于企业级应用。
关键要点
-
前沿大语言模型(LLM)在复杂文档处理中的准确性仍有不足,依赖截图的解析方法存在问题。
-
截图解析方法缺乏企业元数据和信心评分,无法满足生产工作流的需求。
-
维护成本高,构建和维护提示需要大量人力,难以适应多种文档类型。
-
LlamaCloud结合LLM与传统解析技术,旨在提高准确性并降低成本,适用于企业级应用。
-
传统OCR解决方案逐渐过时,LLM在处理标准文档方面表现更好,但在边缘案例上仍有不足。
-
截图方法会丢失关键信息,复杂文档中的层叠文本和嵌入元数据难以提取。
-
LlamaCloud通过提取层叠文本和元数据,结合视觉模型,提供更高的准确性。
-
企业级应用需要信心评分、边界框和来源引用等元数据,LlamaCloud提供这些信息。
-
上下文工程是新兴的AI工程技能,维护提示和适应多种文档类型需要持续的人力投入。
-
企业需要一致的解析方法,LlamaCloud提供标准化的提取架构,简化维护工作。
-
直接调用LLM API会引发操作性挑战,如速率限制、内容过滤和不可预测的成本。
-
LlamaCloud通过页面缓存、去重和异步处理等方式解决了这些操作性问题。
-
未来的文档处理将是LLM驱动的,最佳方案是结合前沿模型的智能与企业应用的操作卓越性。
延伸解读
LLM的局限性与企业需求
尽管前沿大语言模型(LLM)在处理标准文档方面表现出色,但在复杂文档的解析中仍存在准确性不足的问题。企业在选择文档处理方案时,需关注模型是否能提供必要的元数据,如信心评分和边界框,以确保生产工作流的顺利进行。
维护成本与人力投入
依赖LLM API进行文档解析需要持续的人力投入来维护提示和适应不同文档类型。这种高维护成本可能会导致企业在扩展时面临挑战,因此选择一个标准化的解析解决方案,如LlamaCloud,可以有效降低维护负担。
操作性挑战与解决方案
直接调用LLM API可能会引发速率限制、内容过滤和不可预测的成本等操作性挑战。LlamaCloud通过页面缓存和异步处理等方式,解决了这些问题,为企业提供了更可靠的文档处理能力。
延伸问答
LLM在复杂文档处理中的准确性如何?
LLM在复杂文档处理中的准确性仍有不足,尤其是在处理密集文档时,容易出现错误和遗漏。
为什么截图解析方法不适合企业级应用?
截图解析方法缺乏企业元数据和信心评分,无法满足生产工作流的需求,且维护成本高。
LlamaCloud如何提高文档解析的准确性?
LlamaCloud结合LLM与传统解析技术,通过提取层叠文本和元数据,提供更高的准确性。
企业在文档处理时需要哪些元数据?
企业需要信心评分、边界框和来源引用等元数据,以支持审核和质量控制。
直接调用LLM API会遇到哪些操作性挑战?
直接调用LLM API可能面临速率限制、内容过滤和不可预测的成本等操作性挑战。
LlamaCloud如何解决文档处理中的成本问题?
LlamaCloud通过页面缓存、去重和异步处理等方式,优化处理成本并提高效率。
