
Graviton 优化 Agentic RL 沙箱层:架构与成本优势分析
内容提要
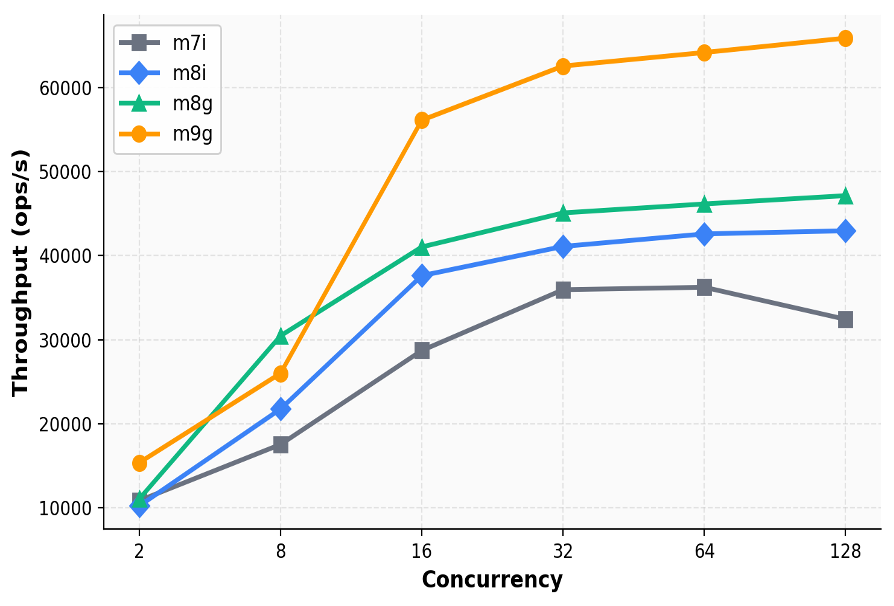
本文分析了基于Graviton的Agentic RL沙盒层的成本优化,指出使用Graviton5的m9g实例可将沙盒层成本降低约41%。沙盒层在Agentic RL训练中是CPU密集型,与GPU训练并行,影响整体训练效率。基准测试显示,Graviton在处理高并发请求时性能显著优于Intel实例,整体迁移至Graviton可有效降低训练成本并提升性能。
关键要点
-
基于Graviton5的m9g实例可将Agentic RL沙盒层成本降低约41%。
-
沙盒层在Agentic RL训练中是CPU密集型,与GPU训练并行,影响整体训练效率。
-
Graviton在处理高并发请求时性能显著优于Intel实例。
-
整体迁移至Graviton可有效降低训练成本并提升性能。
-
沙盒层的工作负载特征一致,适用于多种Agentic RL训练范式。
延伸解读
Graviton的架构优势
Graviton处理器在处理高并发请求时展现出显著的性能优势,尤其是在CPU密集型的Agentic RL沙盒层中。由于Graviton的设计优化了多核并行处理能力,使得在相同的工作负载下,其性能往往超过Intel实例。这一特性使得Graviton成为沙盒层的理想选择,能够有效降低训练成本并提升整体效率。
成本优化的实际影响
迁移至Graviton5的m9g实例后,Agentic RL沙盒层的成本可降低约41%。这一显著的成本节省不仅体现在直接的计算费用上,还能减少训练过程中的等待时间,从而提高训练效率。对于希望降低AI训练成本的团队而言,迁移至Graviton是一个值得考虑的策略。
沙盒层的工作负载特征
沙盒层在Agentic RL训练中承担着重要的角色,其工作负载特征与多种训练范式高度一致。这意味着,针对沙盒层的优化不仅能提升当前训练的效率,还能为未来的多种Agentic RL应用提供支持。因此,理解沙盒层的特性对于进行有效的架构选择和成本评估至关重要。
延伸问答
Graviton5的m9g实例如何降低Agentic RL沙盒层的成本?
使用Graviton5的m9g实例可将Agentic RL沙盒层的成本降低约41%。
沙盒层在Agentic RL训练中扮演什么角色?
沙盒层是CPU密集型的,负责执行真实环境中的工具调用和代码,影响整体训练效率。
Graviton与Intel实例在处理高并发请求时的性能差异如何?
基准测试显示,Graviton在处理高并发请求时性能显著优于Intel实例。
为什么沙盒层适合迁移到Graviton架构?
沙盒层的负载形状是fan-out HTTP,Graviton的高核数和低功耗设计非常契合这种需求。
在Agentic RL训练中,沙盒层的工作负载特征是什么?
沙盒层的工作负载特征一致,适用于多种Agentic RL训练范式,主要是CPU密集型的任务。
如何将沙盒层迁移到Graviton?
迁移工作量集中在构建时,运行时几乎没有改动,主要是构建多架构镜像。
